
أعلنت شركة Apple وشركة Nvidia مؤخرًا عن تعاون يهدف إلى تسريع وتحسين سرعة الاستدلال في نماذج اللغة الكبيرة (LLMs).
ولمعالجة عدم الكفاءة ونطاق الذاكرة المحدود لاستدلال LLM الانحداري التقليدي، أصدر باحثو التعلم الآلي في Apple تقنية فك تشفير تخمينية تسمى "ReDrafter" (نموذج المسودة المتكررة) مفتوحة المصدر في وقت سابق من عام 2024.
حاليًا، تم دمج ReDrafter في حل الاستدلال القابل للتطوير من Nvidia "TensorRT-LLM". هذا الحل عبارة عن مكتبة مفتوحة المصدر تعتمد على إطار عمل مُجمِّع التعلم العميق "TensorRT"، وهو مصمم خصيصًا لتحسين استدلال LLM ودعم طرق فك التشفير المضاربة مثل "Medusa".
ومع ذلك، نظرًا لأن خوارزميات ReDrafter تستخدم مشغلات لم يتم استخدامها سابقًا، فقد أضافت Nvidia مشغلات جديدة أو جعلت المشغلات الموجودة متاحة للعامة، مما عزز بشكل كبير قدرة TensorRT-LLM على التكيف مع النماذج المعقدة وطرق فك التشفير.
يُقال إن ReDrafter يعمل على تسريع عملية الاستدلال للنماذج اللغوية الكبيرة (LLM) من خلال ثلاث تقنيات رئيسية:
- نموذج مشروع RNN
- خوارزمية الانتباه الشجري الديناميكي
- دورة تدريبية حول تقطير المعرفة
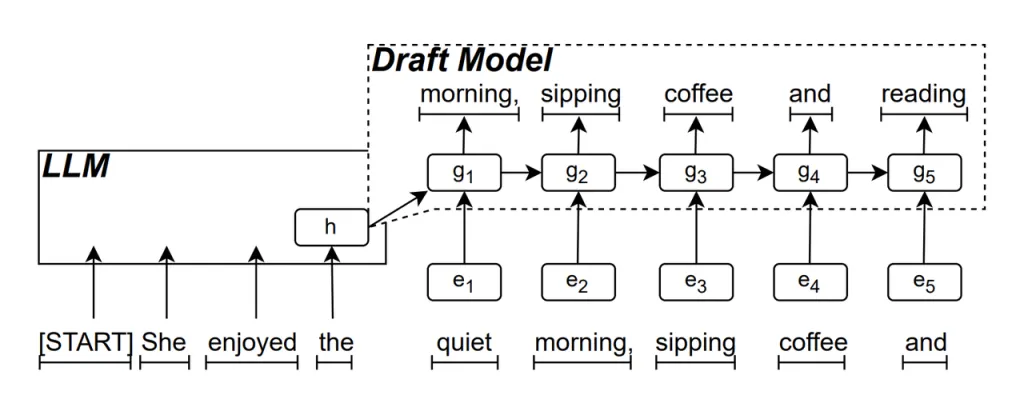
نموذج مشروع RNN هذا هو الجزء الأساسي من ReDrafter. فهو يستخدم شبكة عصبية متكررة (RNN) للتنبؤ بتسلسل الكلمات المحتمل التالي استنادًا إلى الحالات المخفية لـ LLM. وهذا يلتقط التبعيات الزمنية ويحسن دقة التنبؤ.
طريقة عمل هذا النموذج هي: عندما يقوم LLM بإنشاء نص، فإنه يقوم أولاً بإنشاء كلمة أولية، ثم يستخدم نموذج مسودة RNN هذه الكلمة وحالة الطبقة المخفية الأخيرة من LLM كمدخل لإجراء بحث شعاعي، مما يؤدي إلى إنشاء تسلسلات متعددة من الكلمات المرشحة.
على عكس نماذج LLM الانحدارية الذاتية التقليدية التي تولد كلمة واحدة في كل مرة، يمكن لـ ReDrafter توليد كلمات متعددة في كل خطوة فك تشفير من خلال تنبؤات نموذج RNN Draft، مما يقلل بشكل كبير من عدد المرات التي يجب فيها استدعاء LLM للتحقق من الصحة، وبالتالي تحسين سرعة الاستدلال الإجمالية.
خوارزمية الانتباه الشجري الديناميكي هي خوارزمية تعمل على تحسين نتائج البحث الشعاعي.
أثناء عملية البحث عن الحزمة، يتم إنشاء تسلسلات مرشحة متعددة، والتي غالبًا ما يكون لها نفس البداية. تحدد خوارزمية الانتباه الشجري الديناميكي هذه البدايات المشتركة وتزيلها من الكلمات التي تحتاج إلى التحقق من صحتها، مما يقلل من كمية البيانات التي يحتاج LLM إلى معالجتها.
في بعض الحالات، يمكن لهذه الخوارزمية تقليل عدد الكلمات التي تحتاج إلى التحقق من صحتها بنسبة تتراوح بين 30% و60%. وهذا يعني أنه باستخدام خوارزمية Dynamic Tree Attention، يمكن لـ ReDrafter الاستفادة من الموارد الحسابية بكفاءة أكبر، مما يؤدي إلى تحسين سرعة الاستدلال بشكل أكبر.
تقطير المعرفة هي تقنية ضغط نموذجية تنقل المعرفة من نموذج كبير ومعقد (نموذج المعلم) إلى نموذج أصغر وأبسط (نموذج الطالب). في ReDrafter، يعمل نموذج RNN Draft كنموذج الطالب، ويتعلم من LLM (نموذج المعلم) من خلال تقطير المعرفة.
بالتفصيل، أثناء عملية تدريب التقطير، يوفر نموذج اللغة الكبير (LLM) سلسلة من "توزيعات الاحتمالات" للكلمات المحتملة التالية. يستخدم المطورون بيانات توزيع الاحتمالات هذه لتدريب نموذج مسودة الشبكة العصبية المتكررة (RNN)، ثم حساب الفرق بين توزيعات الاحتمالات للنموذجين، وتقليل هذا الفرق من خلال خوارزميات التحسين.
أثناء هذه العملية، يتعلم نموذج مسودة RNN بشكل مستمر أنماط التنبؤ بالاحتمالات الخاصة بـ LLM، مما يمكنه من إنشاء نص مشابه لـ LLM في التطبيقات العملية.
من خلال تدريب تقطير المعرفة، يلتقط نموذج مسودة RNN قواعد وأنماط اللغة بشكل أفضل، وبالتالي يتنبأ بشكل أكثر دقة بإخراج LLM. ونظرًا لحجمه الأصغر وتكاليفه الحسابية المنخفضة، فإنه يحسن بشكل كبير الأداء العام لـ ReDrafter في ظل ظروف الأجهزة المحدودة.
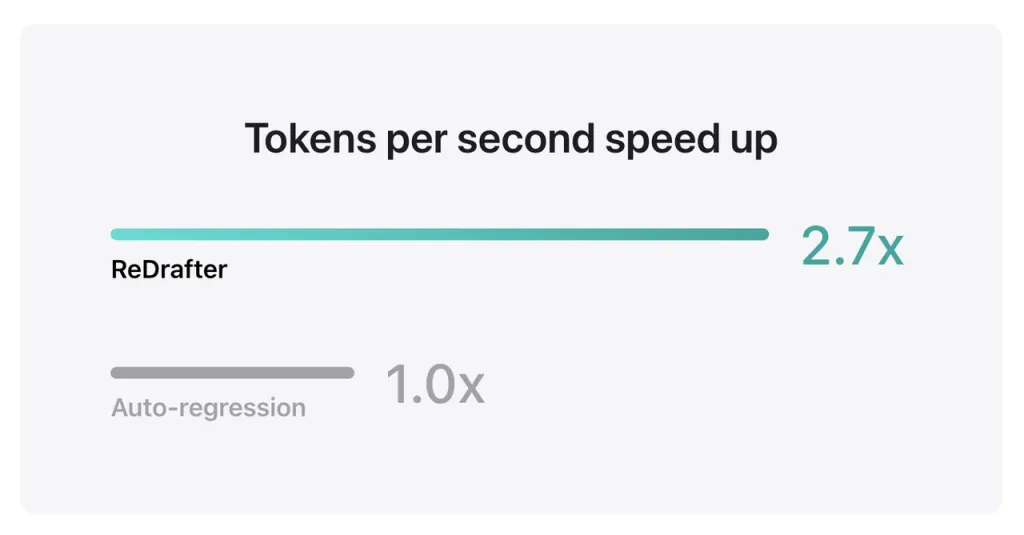
تظهر نتائج اختبارات Apple القياسية أنه عند استخدام نموذج الإنتاج مع مليارات المعلمات المتكاملة مع TensorRT-LLM من ReDrafter على وحدة معالجة الرسومات NVIDIA H100، زاد عدد الرموز المميزة التي تم إنشاؤها في الثانية الواحدة بواسطة Greedy Decoding بمقدار 2.7 مرة.
بالإضافة إلى ذلك، حقق برنامج ReDrafter تحسنًا في سرعة الاستدلال بمقدار 2 مرة على وحدة معالجة الرسوميات M2.3 Ultra Metal من Apple. وذكر باحثو Apple، "نظرًا لاستخدام LLMs بشكل متزايد لتشغيل تطبيقات الإنتاج، فإن تحسين كفاءة الاستدلال يمكن أن يؤثر على التكاليف الحسابية ويقلل من زمن الوصول للمستخدم النهائي".
ومن الجدير بالذكر أنه مع الحفاظ على جودة الإخراج، يقلل ReDrafter الطلب على موارد وحدة معالجة الرسومات، مما يسمح لـ LLMs بالعمل بكفاءة حتى في البيئات ذات الموارد المحدودة، مما يوفر إمكانيات جديدة لاستخدام LLMs على منصات الأجهزة المختلفة.
وقد قامت شركة Apple بالفعل بجعل هذه التكنولوجيا مفتوحة المصدر على GitHub، وفي المستقبل من المرجح أن تشمل الشركات المستفيدة منها أكثر من مجرد NVIDIA.
مصدر من إيفان
إخلاء المسؤولية: يتم توفير المعلومات المذكورة أعلاه بواسطة ifanr.com، بشكل مستقل عن Chovm.com. لا تقدم Chovm.com أي تعهدات أو ضمانات فيما يتعلق بجودة وموثوقية البائع والمنتجات. ينكر موقع Chovm.com صراحةً أي مسؤولية عن الانتهاكات المتعلقة بحقوق الطبع والنشر للمحتوى.



