
Kürzlich gaben Apple und Nvidia eine Zusammenarbeit bekannt, deren Ziel die Beschleunigung und Optimierung der Inferenzgeschwindigkeit großer Sprachmodelle (LLMs) ist.
Um die Ineffizienzen und die begrenzte Speicherbandbreite der herkömmlichen autoregressiven LLM-Inferenz zu beheben, haben die Forscher für maschinelles Lernen von Apple Anfang 2024 eine spekulative Dekodierungstechnik namens „ReDrafter“ (Recurrent Draft Model) veröffentlicht und als Open Source zur Verfügung gestellt.
Derzeit wurde ReDrafter in Nvidias skalierbare Inferenzlösung „TensorRT-LLM“ integriert. Diese Lösung ist eine Open-Source-Bibliothek, die auf dem Deep-Learning-Compiler-Framework „TensorRT“ basiert und speziell zur Optimierung der LLM-Inferenz und zur Unterstützung spekulativer Dekodierungsmethoden wie „Medusa“ entwickelt wurde.
Da die Algorithmen von ReDrafter jedoch bisher nicht verwendete Operatoren verwenden, hat Nvidia neue Operatoren hinzugefügt oder vorhandene öffentlich gemacht, wodurch die Anpassungsfähigkeit von TensorRT-LLM an komplexe Modelle und Dekodierungsmethoden erheblich verbessert wurde.
Es wird berichtet, dass ReDrafter den Inferenzprozess großer Sprachmodelle (LLM) durch drei Schlüsseltechnologien beschleunigt:
- RNN-Entwurfsmodell
- Dynamischer Tree-Attention-Algorithmus
- Schulung zur Wissensdestillation
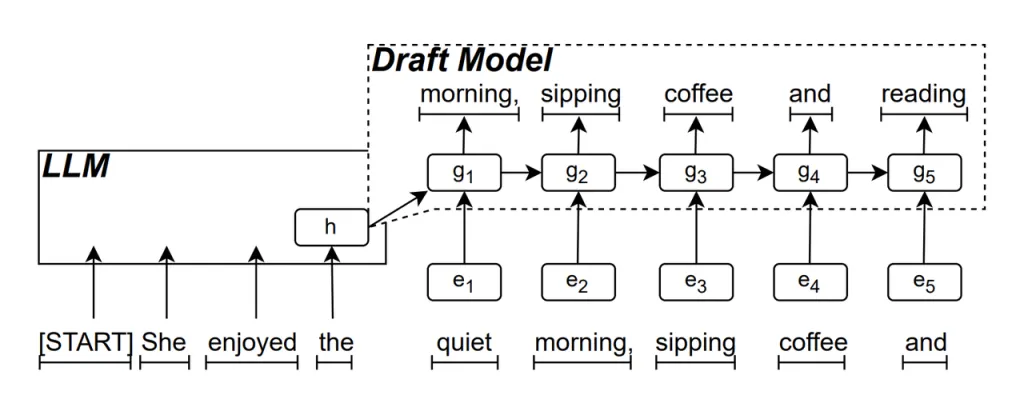
RNN-Entwurfsmodell ist der Kernbestandteil von ReDrafter. Es verwendet ein rekurrentes neuronales Netzwerk (RNN), um die nächste mögliche Wortfolge basierend auf den verborgenen Zuständen des LLM vorherzusagen. Dadurch werden zeitliche Abhängigkeiten erfasst und die Vorhersagegenauigkeit verbessert.
Die Funktionsweise dieses Modells ist folgende: Wenn das LLM Text generiert, generiert es zuerst ein Anfangswort. Anschließend verwendet das RNN-Entwurfsmodell dieses Wort und den verborgenen Zustand des LLM der letzten Ebene als Eingabe, um eine Strahlensuche durchzuführen und mehrere Kandidatenwortfolgen zu generieren.
Im Gegensatz zu herkömmlichen autoregressiven LLMs, die jeweils ein Wort generieren, kann ReDrafter durch die Vorhersagen des RNN-Entwurfsmodells in jedem Dekodierungsschritt mehrere Wörter generieren. Dadurch wird die Anzahl der zur Validierung erforderlichen LLM-Aufrufe erheblich reduziert und die allgemeine Inferenzgeschwindigkeit verbessert.
Dynamischer Tree-Attention-Algorithmus ist ein Algorithmus, der die Ergebnisse der Strahlensuche optimiert.
Während des Beam-Search-Prozesses werden mehrere Kandidatensequenzen generiert, die oft den gleichen Anfang haben. Der Dynamic Tree Attention Algorithm erkennt diese gemeinsamen Anfänge und entfernt sie aus den zu validierenden Wörtern, wodurch die Datenmenge, die das LLM verarbeiten muss, reduziert wird.
In einigen Fällen kann dieser Algorithmus die Anzahl der zu validierenden Wörter um 30 bis 60 % reduzieren. Dies bedeutet, dass ReDrafter mit dem Dynamic Tree Attention Algorithm die Rechenressourcen effizienter nutzen und so die Inferenzgeschwindigkeit weiter verbessern kann.
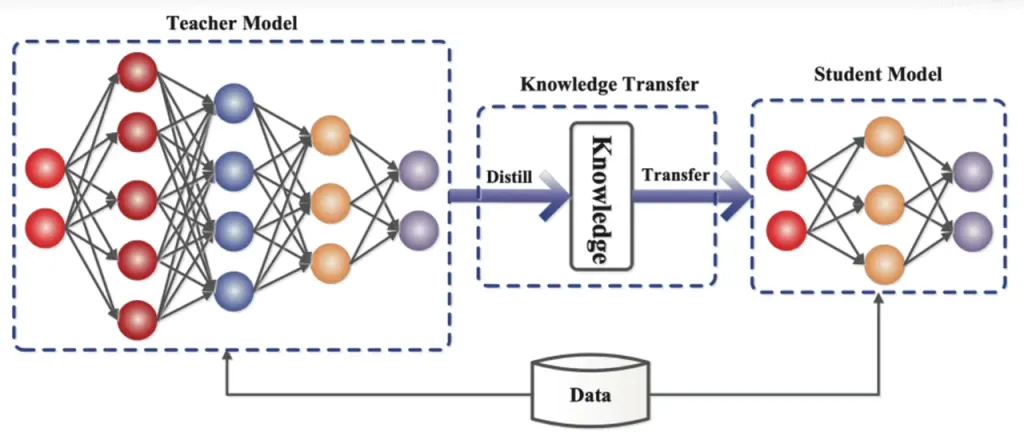
Wissensdestillation ist eine Modellkomprimierungstechnik, die das Wissen von einem großen, komplexen Modell (Lehrermodell) auf ein kleineres, einfacheres Modell (Schülermodell) überträgt. In ReDrafter fungiert das RNN-Entwurfsmodell als Schülermodell und lernt durch Wissensdestillation vom LLM (Lehrermodell).
Im Einzelnen liefert während des Destillationstrainingsprozesses ein großes Sprachmodell (LLM) eine Reihe von „Wahrscheinlichkeitsverteilungen“ für die nächsten möglichen Wörter. Entwickler verwenden diese Wahrscheinlichkeitsverteilungsdaten, um ein Recurrent Neural Network (RNN)-Entwurfsmodell zu trainieren, berechnen dann den Unterschied zwischen den Wahrscheinlichkeitsverteilungen der beiden Modelle und minimieren diesen Unterschied durch Optimierungsalgorithmen.
Während dieses Prozesses lernt das RNN-Entwurfsmodell kontinuierlich die Wahrscheinlichkeitsvorhersagemuster des LLM und kann so in praktischen Anwendungen Text generieren, der dem LLM ähnelt.
Durch das Training mit Wissensdestillation erfasst das RNN-Entwurfsmodell die Regeln und Muster der Sprache besser und kann so die Ausgabe des LLM genauer vorhersagen. Aufgrund seiner geringeren Größe und der geringeren Rechenkosten verbessert es die Gesamtleistung von ReDrafter unter eingeschränkten Hardwarebedingungen erheblich.
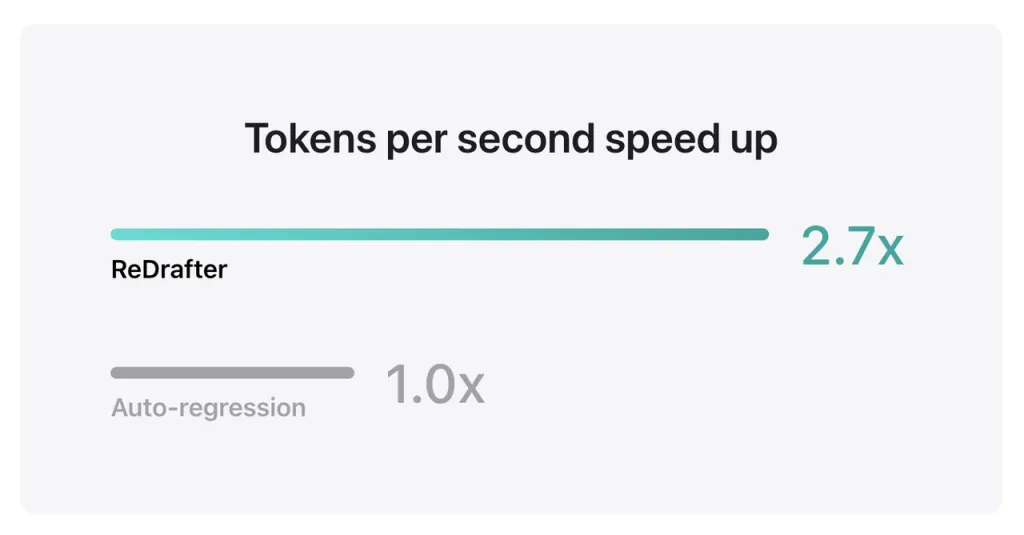
Die Benchmark-Ergebnisse von Apple zeigen, dass sich bei Verwendung des Produktionsmodells mit Milliarden von Parametern, die in TensorRT-LLM von ReDrafter auf der NVIDIA H100 GPU integriert sind, die Anzahl der pro Sekunde durch Greedy Decoding generierten Token um das 2.7-fache erhöht.
Darüber hinaus erreichte ReDrafter auf Apples eigener M2 Ultra Metal GPU eine 2.3-fache Verbesserung der Inferenzgeschwindigkeit. Die Forscher von Apple erklärten: „Da LLMs zunehmend zum Antreiben von Produktionsanwendungen verwendet werden, kann eine Verbesserung der Inferenzeffizienz die Rechenkosten beeinflussen und die Latenzzeit auf Benutzerseite verringern.“
Es ist erwähnenswert, dass ReDrafter unter Beibehaltung der Ausgabequalität den Bedarf an GPU-Ressourcen reduziert, sodass LLMs auch in Umgebungen mit eingeschränkten Ressourcen effizient ausgeführt werden können und neue Möglichkeiten für die Verwendung von LLMs auf verschiedenen Hardwareplattformen entstehen.
Apple hat diese Technologie bereits auf GitHub als Open Source bereitgestellt und in Zukunft werden wahrscheinlich nicht nur NVIDIA, sondern auch andere Unternehmen davon profitieren.
Quelle aus wenn ein
Haftungsausschluss: Die oben aufgeführten Informationen werden von ifanr.com unabhängig von Chovm.com bereitgestellt. Chovm.com übernimmt keine Zusicherungen und Gewährleistungen hinsichtlich der Qualität und Zuverlässigkeit des Verkäufers und der Produkte. Chovm.com lehnt ausdrücklich jegliche Haftung für Verstöße gegen das Urheberrecht von Inhalten ab.



