
Recientemente, Apple y Nvidia anunciaron una colaboración destinada a acelerar y optimizar la velocidad de inferencia de modelos de lenguaje grandes (LLM).
Para abordar las ineficiencias y el ancho de banda de memoria limitado de la inferencia LLM autorregresiva tradicional, los investigadores de aprendizaje automático de Apple lanzaron y publicaron en código abierto una técnica de decodificación especulativa llamada "ReDrafter" (Recurrent Draft Model) a principios de 2024.
Actualmente, ReDrafter se ha integrado en la solución de inferencia escalable “TensorRT-LLM” de Nvidia. Esta solución es una biblioteca de código abierto basada en el marco de compilación de aprendizaje profundo “TensorRT”, diseñada específicamente para optimizar la inferencia LLM y admitir métodos de decodificación especulativa como “Medusa”.
Sin embargo, dado que los algoritmos de ReDrafter utilizan operadores no utilizados anteriormente, Nvidia ha agregado nuevos operadores o ha hecho públicos los existentes, mejorando significativamente la capacidad de TensorRT-LLM para adaptarse a modelos complejos y métodos de decodificación.
Se informa que ReDrafter acelera el proceso de inferencia de modelos de lenguaje grandes (LLM) a través de tres tecnologías clave:
- Borrador del modelo RNN
- Algoritmo de atención de árbol dinámico
- Formación en destilación de conocimientos
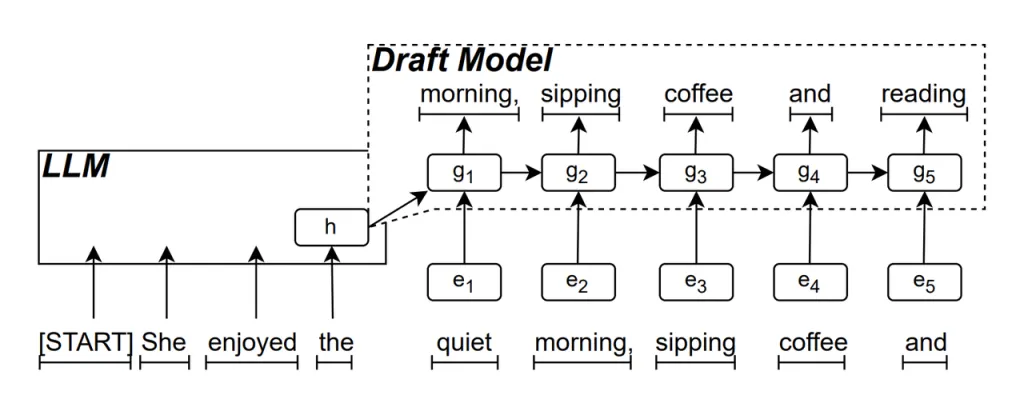
Borrador del modelo RNN es la parte central de ReDrafter. Utiliza una red neuronal recurrente (RNN) para predecir la siguiente secuencia de palabras posible en función de los estados ocultos de la LLM. Esto captura dependencias temporales y mejora la precisión de la predicción.
La forma en que funciona este modelo es la siguiente: cuando el LLM genera texto, primero genera una palabra inicial, luego el modelo borrador RNN utiliza esta palabra y el estado oculto de la última capa del LLM como entrada para realizar una búsqueda de haz, generando múltiples secuencias de palabras candidatas.
A diferencia de los LLM autorregresivos tradicionales que generan una palabra a la vez, ReDrafter puede generar múltiples palabras en cada paso de decodificación a través de las predicciones del modelo borrador de RNN, lo que reduce significativamente la cantidad de veces que es necesario llamar al LLM para validación, mejorando así la velocidad de inferencia general.
Algoritmo de atención de árbol dinámico es un algoritmo que optimiza los resultados de búsqueda de haces.
Durante el proceso de búsqueda de haces, se generan múltiples secuencias candidatas, que a menudo tienen el mismo comienzo. El algoritmo de atención de árbol dinámico identifica estos comienzos comunes y los elimina de las palabras que deben validarse, lo que reduce la cantidad de datos que el LLM necesita procesar.
En algunos casos, este algoritmo puede reducir la cantidad de palabras que se deben validar entre un 30 % y un 60 %. Esto significa que con el algoritmo de atención de árbol dinámico, ReDrafter puede utilizar los recursos computacionales de manera más eficiente, mejorando aún más la velocidad de inferencia.
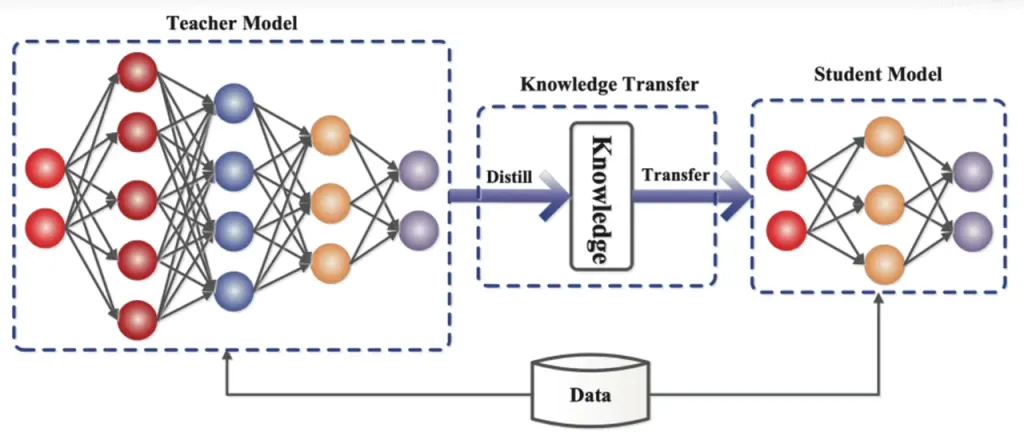
Destilación del conocimiento es una técnica de compresión de modelos que transfiere el conocimiento de un modelo grande y complejo (modelo del profesor) a un modelo más pequeño y simple (modelo del estudiante). En ReDrafter, el modelo borrador de RNN actúa como el modelo del estudiante, aprendiendo del LLM (modelo del profesor) a través de la destilación del conocimiento.
En detalle, durante el proceso de entrenamiento de destilación, un modelo de lenguaje grande (LLM) proporciona una serie de "distribuciones de probabilidad" para las siguientes palabras posibles. Los desarrolladores utilizan estos datos de distribución de probabilidad para entrenar un modelo preliminar de red neuronal recurrente (RNN), luego calculan la diferencia entre las distribuciones de probabilidad de los dos modelos y minimizan esta diferencia a través de algoritmos de optimización.
Durante este proceso, el modelo de borrador de RNN aprende continuamente los patrones de predicción de probabilidad del LLM, lo que le permite generar texto similar al LLM en aplicaciones prácticas.
A través del entrenamiento de destilación de conocimientos, el modelo de borrador de RNN captura mejor las reglas y los patrones del lenguaje, lo que permite predecir con mayor precisión el resultado del LLM. Debido a su menor tamaño y menor costo computacional, mejora significativamente el rendimiento general de ReDrafter en condiciones de hardware limitadas.
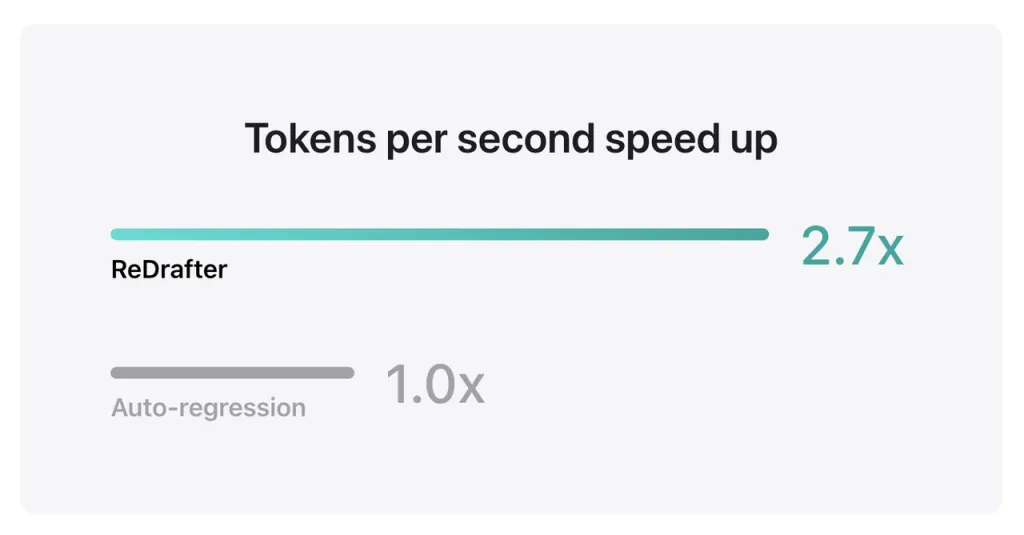
Los resultados de referencia de Apple muestran que al utilizar el modelo de producción con miles de millones de parámetros integrados con TensorRT-LLM de ReDrafter en la GPU NVIDIA H100, la cantidad de tokens generados por segundo por Greedy Decoding aumentó 2.7 veces.
Además, en la propia GPU M2 Ultra Metal de Apple, ReDrafter logró una mejora de la velocidad de inferencia de 2.3 veces. Los investigadores de Apple afirmaron: "Dado que los LLM se utilizan cada vez más para impulsar aplicaciones de producción, mejorar la eficiencia de la inferencia puede afectar los costos computacionales y reducir la latencia del usuario final".
Vale la pena señalar que, al tiempo que mantiene la calidad de salida, ReDrafter reduce la demanda de recursos de la GPU, lo que permite que los LLM se ejecuten de manera eficiente incluso en entornos con recursos limitados, lo que brinda nuevas posibilidades para el uso de los LLM en varias plataformas de hardware.
Apple ya ha publicado esta tecnología en código abierto en GitHub y, en el futuro, es probable que entre las empresas que se beneficien de ella se incluyan más empresas que NVIDIA.
Fuente de ifanr
Descargo de responsabilidad: La información establecida anteriormente es proporcionada por ifanr.com, independientemente de Chovm.com. Chovm.com no representa ni garantiza la calidad y confiabilidad del vendedor y los productos. Chovm.com renuncia expresamente a cualquier responsabilidad por violaciones relacionadas con los derechos de autor del contenido.




 বাংলা
বাংলা Nederlands
Nederlands English
English Français
Français Deutsch
Deutsch हिन्दी
हिन्दी Bahasa Indonesia
Bahasa Indonesia Italiano
Italiano 日本語
日本語 한국어
한국어 Bahasa Melayu
Bahasa Melayu മലയാളം
മലയാളം پښتو
پښتو فارسی
فارسی Polski
Polski Português
Português Русский
Русский Español
Español Kiswahili
Kiswahili ไทย
ไทย Türkçe
Türkçe اردو
اردو Tiếng Việt
Tiếng Việt isiXhosa
isiXhosa Zulu
Zulu