
Baru-baru ini, Apple dan Nvidia mengumumkan kolaborasi yang bertujuan untuk mempercepat dan mengoptimalkan kecepatan inferensi model bahasa besar (LLM).
Untuk mengatasi inefisiensi dan keterbatasan bandwidth memori dari inferensi LLM autoregresif tradisional, para peneliti pembelajaran mesin Apple merilis dan menjadikan teknik dekode spekulatif yang disebut “ReDrafter” (Recurrent Draft Model) sebagai sumber terbuka pada awal tahun 2024.
Saat ini, ReDrafter telah diintegrasikan ke dalam solusi inferensi skalabel Nvidia “TensorRT-LLM.” Solusi ini adalah pustaka sumber terbuka yang didasarkan pada kerangka kerja penyusun pembelajaran mendalam “TensorRT”, yang secara khusus dirancang untuk mengoptimalkan inferensi LLM dan mendukung metode dekode spekulatif seperti “Medusa.”
Namun, karena algoritme ReDrafter menggunakan operator yang sebelumnya tidak digunakan, Nvidia telah menambahkan operator baru atau mempublikasikan operator yang sudah ada, yang secara signifikan meningkatkan kemampuan TensorRT-LLM untuk beradaptasi dengan model kompleks dan metode decoding.
Dilaporkan bahwa ReDrafter mempercepat proses inferensi model bahasa besar (LLM) melalui tiga teknologi utama:
- Draf Model RNN
- Algoritma Perhatian Pohon Dinamis
- Pelatihan Penyulingan Pengetahuan
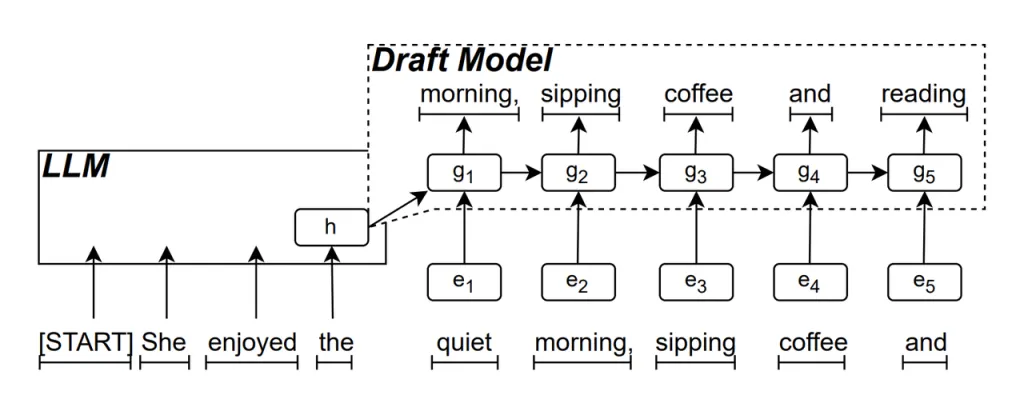
Draf Model RNN merupakan bagian inti dari ReDrafter. Ia menggunakan Recurrent Neural Network (RNN) untuk memprediksi kemungkinan urutan kata berikutnya berdasarkan status tersembunyi dari LLM. Hal ini menangkap ketergantungan temporal dan meningkatkan akurasi prediksi.
Cara kerja model ini adalah: saat LLM menghasilkan teks, pertama-tama ia menghasilkan kata awal, lalu Draf Model RNN menggunakan kata ini dan status tersembunyi LLM pada lapisan terakhir sebagai input untuk melakukan penelusuran berkas, yang menghasilkan beberapa rangkaian kata kandidat.
Tidak seperti LLM autoregresif tradisional yang menghasilkan satu kata dalam satu waktu, ReDrafter dapat menghasilkan beberapa kata di setiap langkah dekode melalui prediksi Model Draf RNN, yang secara signifikan mengurangi jumlah kali LLM perlu dipanggil untuk validasi, sehingga meningkatkan kecepatan inferensi keseluruhan.
Algoritma Perhatian Pohon Dinamis adalah algoritma yang mengoptimalkan hasil pencarian sinar.
Selama proses pencarian berkas, beberapa urutan kandidat dihasilkan, yang sering kali memiliki awal yang sama. Algoritme Perhatian Pohon Dinamis mengidentifikasi awal yang umum ini dan menghapusnya dari kata-kata yang perlu divalidasi, sehingga mengurangi jumlah data yang perlu diproses oleh LLM.
Dalam beberapa kasus, algoritma ini dapat mengurangi jumlah kata yang perlu divalidasi hingga 30% hingga 60%. Ini berarti bahwa dengan Algoritma Dynamic Tree Attention, ReDrafter dapat memanfaatkan sumber daya komputasi secara lebih efisien, yang selanjutnya meningkatkan kecepatan inferensi.
Penyulingan Pengetahuan adalah teknik kompresi model yang mentransfer pengetahuan dari model yang besar dan kompleks (model guru) ke model yang lebih kecil dan lebih sederhana (model siswa). Dalam ReDrafter, Model Draft RNN bertindak sebagai model siswa, belajar dari LLM (model guru) melalui penyulingan pengetahuan.
Secara rinci, selama proses pelatihan distilasi, model bahasa besar (LLM) menyediakan serangkaian "distribusi probabilitas" untuk kata-kata yang mungkin muncul berikutnya. Pengembang menggunakan data distribusi probabilitas ini untuk melatih model rancangan Jaringan Syaraf Tiruan Berulang (RNN), lalu menghitung perbedaan antara distribusi probabilitas kedua model, dan meminimalkan perbedaan ini melalui algoritme pengoptimalan.
Selama proses ini, rancangan model RNN terus mempelajari pola prediksi probabilitas LLM, yang memungkinkannya menghasilkan teks yang mirip dengan LLM dalam aplikasi praktis.
Melalui pelatihan penyulingan pengetahuan, model rancangan RNN menangkap aturan dan pola bahasa dengan lebih baik, sehingga memprediksi keluaran LLM dengan lebih akurat. Karena ukurannya yang lebih kecil dan biaya komputasi yang lebih rendah, model ini secara signifikan meningkatkan kinerja ReDrafter secara keseluruhan dalam kondisi perangkat keras yang terbatas.
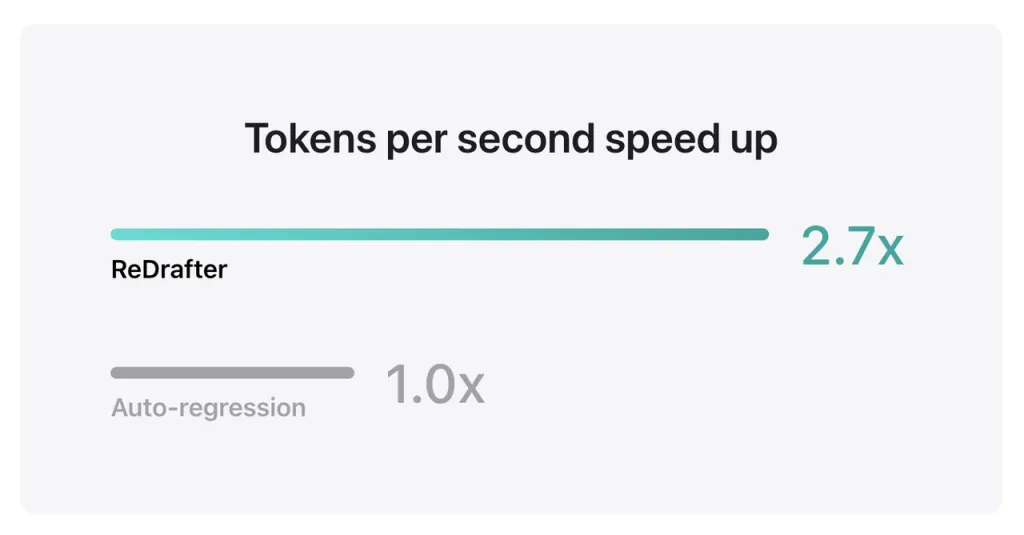
Hasil benchmark Apple menunjukkan bahwa saat menggunakan model produksi dengan miliaran parameter yang terintegrasi dengan TensorRT-LLM ReDrafter pada GPU NVIDIA H100, jumlah token yang dihasilkan per detik oleh Greedy Decoding meningkat 2.7 kali lipat.
Selain itu, pada GPU M2 Ultra Metal milik Apple sendiri, ReDrafter mencapai peningkatan kecepatan inferensi sebanyak 2.3 kali lipat. Para peneliti Apple menyatakan, “Karena LLM semakin banyak digunakan untuk menjalankan aplikasi produksi, peningkatan efisiensi inferensi dapat memengaruhi biaya komputasi dan mengurangi latensi pengguna.”
Perlu dicatat bahwa sambil mempertahankan kualitas keluaran, ReDrafter mengurangi kebutuhan sumber daya GPU, yang memungkinkan LLM berjalan secara efisien bahkan di lingkungan dengan sumber daya terbatas, memberikan kemungkinan baru untuk penggunaan LLM pada berbagai platform perangkat keras.
Apple telah menjadikan teknologi ini sebagai sumber terbuka di GitHub, dan di masa mendatang, perusahaan yang memperoleh manfaat darinya kemungkinan akan mencakup lebih dari sekadar NVIDIA.
Sumber dari jika
Penafian: Informasi yang diuraikan di atas disediakan oleh ifanr.com, independen dari Chovm.com. Chovm.com tidak membuat pernyataan dan jaminan mengenai kualitas dan keandalan penjual dan produk. Chovm.com secara tegas melepaskan tanggung jawab apa pun atas pelanggaran yang berkaitan dengan hak cipta konten.



