
Di recente, Apple e Nvidia hanno annunciato una collaborazione volta ad accelerare e ottimizzare la velocità di inferenza dei modelli linguistici di grandi dimensioni (LLM).
Per risolvere le inefficienze e la limitata larghezza di banda della memoria dell'inferenza LLM autoregressiva tradizionale, all'inizio del 2024 i ricercatori di apprendimento automatico di Apple hanno rilasciato e reso open source una tecnica di decodifica speculativa chiamata "ReDrafter" (Recurrent Draft Model).
Attualmente, ReDrafter è stato integrato nella soluzione di inferenza scalabile di Nvidia "TensorRT-LLM". Questa soluzione è una libreria open source basata sul framework del compilatore di deep learning "TensorRT", specificamente progettata per ottimizzare l'inferenza LLM e supportare metodi di decodifica speculativa come "Medusa".
Tuttavia, poiché gli algoritmi di ReDrafter utilizzano operatori in precedenza non utilizzati, Nvidia ha aggiunto nuovi operatori o ha reso pubblici quelli esistenti, migliorando significativamente la capacità di TensorRT-LLM di adattarsi a modelli complessi e metodi di decodifica.
È stato riferito che ReDrafter accelera il processo di inferenza di grandi modelli linguistici (LLM) attraverso tre tecnologie chiave:
- Bozza del modello RNN
- Algoritmo di attenzione dinamica dell'albero
- Formazione sulla distillazione della conoscenza
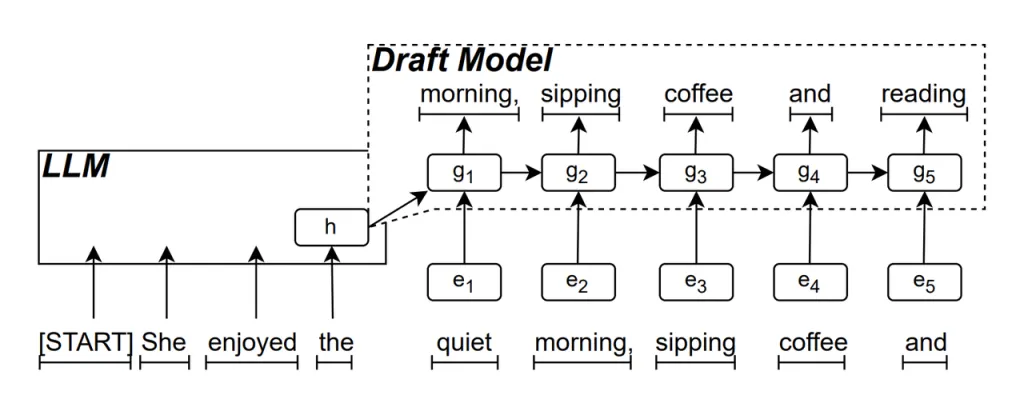
Bozza del modello RNN è la parte centrale di ReDrafter. Utilizza una Recurrent Neural Network (RNN) per predire la successiva possibile sequenza di parole in base agli stati nascosti dell'LLM. Ciò cattura le dipendenze temporali e migliora l'accuratezza della predizione.
Il funzionamento di questo modello è il seguente: quando l'LLM genera del testo, prima genera una parola iniziale, quindi il modello RNN Draft utilizza questa parola e lo stato nascosto dell'ultimo strato dell'LLM come input per eseguire la ricerca del fascio, generando più sequenze di parole candidate.
A differenza dei tradizionali LLM autoregressivi che generano una parola alla volta, ReDrafter può generare più parole a ogni passaggio di decodifica attraverso le previsioni del modello RNN Draft, riducendo significativamente il numero di volte in cui è necessario chiamare l'LLM per la convalida, migliorando così la velocità di inferenza complessiva.
Algoritmo di attenzione dinamica dell'albero è un algoritmo che ottimizza i risultati della ricerca del raggio.
Durante il processo di ricerca del fascio, vengono generate più sequenze candidate, che spesso hanno lo stesso inizio. Il Dynamic Tree Attention Algorithm identifica questi inizi comuni e li rimuove dalle parole che devono essere convalidate, riducendo la quantità di dati che l'LLM deve elaborare.
In alcuni casi, questo algoritmo può ridurre il numero di parole che devono essere convalidate dal 30% al 60%. Ciò significa che con l'algoritmo Dynamic Tree Attention, ReDrafter può utilizzare le risorse di calcolo in modo più efficiente, migliorando ulteriormente la velocità di inferenza.
Distillazione della conoscenza è una tecnica di compressione del modello che trasferisce la conoscenza da un modello grande e complesso (modello insegnante) a un modello più piccolo e semplice (modello studente). In ReDrafter, il modello RNN Draft funge da modello studente, imparando dal LLM (modello insegnante) attraverso la distillazione della conoscenza.
In dettaglio, durante il processo di training di distillazione, un modello linguistico di grandi dimensioni (LLM) fornisce una serie di "distribuzioni di probabilità" per le prossime parole possibili. Gli sviluppatori utilizzano questi dati di distribuzione di probabilità per addestrare un modello di bozza di Recurrent Neural Network (RNN), quindi calcolano la differenza tra le distribuzioni di probabilità dei due modelli e riducono al minimo questa differenza tramite algoritmi di ottimizzazione.
Durante questo processo, il modello di bozza RNN apprende costantemente i modelli di previsione della probabilità dell'LLM, consentendogli di generare testo simile all'LLM nelle applicazioni pratiche.
Attraverso l'addestramento alla distillazione della conoscenza, il modello RNN draft cattura meglio le regole e gli schemi del linguaggio, prevedendo così in modo più accurato l'output dell'LLM. Grazie alle sue dimensioni ridotte e al costo computazionale inferiore, migliora significativamente le prestazioni complessive di ReDrafter in condizioni hardware limitate.
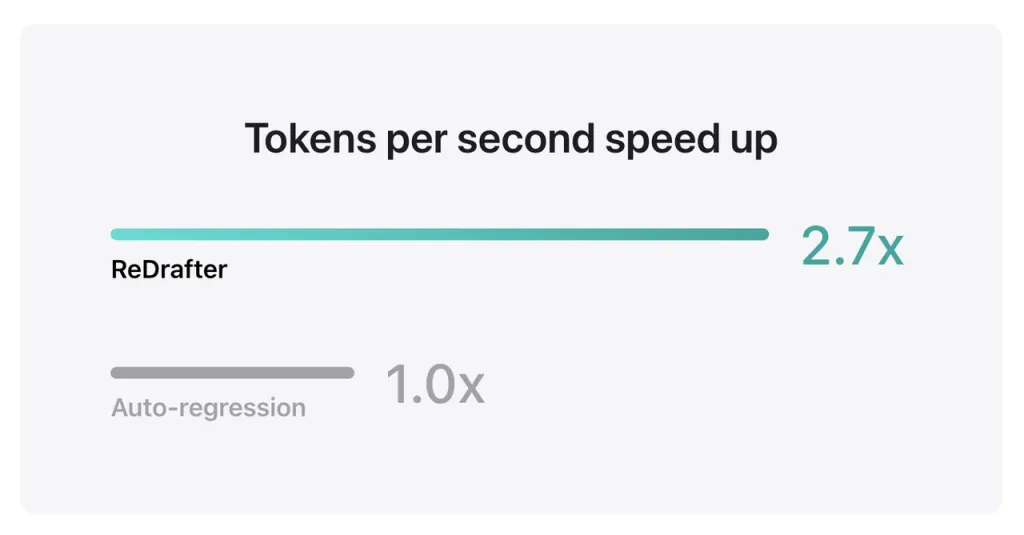
I risultati del benchmark di Apple mostrano che utilizzando il modello di produzione con miliardi di parametri integrati con TensorRT-LLM di ReDrafter sulla GPU NVIDIA H100, il numero di token generati al secondo da Greedy Decoding è aumentato di 2.7 volte.
Inoltre, sulla GPU M2 Ultra Metal di Apple, ReDrafter ha ottenuto un miglioramento della velocità di inferenza di 2.3 volte. I ricercatori di Apple hanno affermato: "Dato che gli LLM sono sempre più utilizzati per guidare le applicazioni di produzione, il miglioramento dell'efficienza di inferenza può avere un impatto sui costi computazionali e ridurre la latenza dell'utente finale".
Vale la pena notare che, pur mantenendo la qualità dell'output, ReDrafter riduce la richiesta di risorse GPU, consentendo ai LLM di funzionare in modo efficiente anche in ambienti con risorse limitate, offrendo nuove possibilità per l'uso dei LLM su varie piattaforme hardware.
Apple ha già reso open source questa tecnologia su GitHub e, in futuro, tra le aziende che ne trarranno vantaggio, probabilmente non ci sarà solo NVIDIA.
Fonte da se uno
Dichiarazione di non responsabilità: le informazioni sopra riportate sono fornite da ifanr.com, indipendentemente da Chovm.com. Chovm.com non rilascia alcuna dichiarazione o garanzia in merito alla qualità e all'affidabilità del venditore e dei prodotti. Chovm.com declina espressamente qualsiasi responsabilità per violazioni relative al diritto d'autore dei contenuti.



