
最近、Apple と Nvidia は、大規模言語モデル (LLM) の推論速度の高速化と最適化を目的としたコラボレーションを発表しました。
従来の自己回帰 LLM 推論の非効率性とメモリ帯域幅の制限に対処するため、Apple の機械学習研究者は 2024 年の初めに「ReDrafter」(Recurrent Draft Model) と呼ばれる推測デコード手法をリリースし、オープンソース化しました。
現在、ReDrafter は Nvidia のスケーラブルな推論ソリューション「TensorRT-LLM」に統合されています。このソリューションは、「TensorRT」ディープラーニング コンパイラ フレームワークに基づくオープンソース ライブラリであり、LLM 推論を最適化し、「Medusa」などの投機的デコード手法をサポートするように特別に設計されています。
ただし、ReDrafter のアルゴリズムではこれまで使用されていなかった演算子が使用されるため、Nvidia は新しい演算子を追加したり、既存の演算子を公開したりして、TensorRT-LLM の複雑なモデルやデコード方法への適応能力を大幅に強化しました。
ReDrafter は、次の 3 つの主要テクノロジーを通じて大規模言語モデル (LLM) の推論プロセスを加速すると報告されています。
- RNN ドラフトモデル
- 動的ツリーアテンションアルゴリズム
- 知識抽出トレーニング
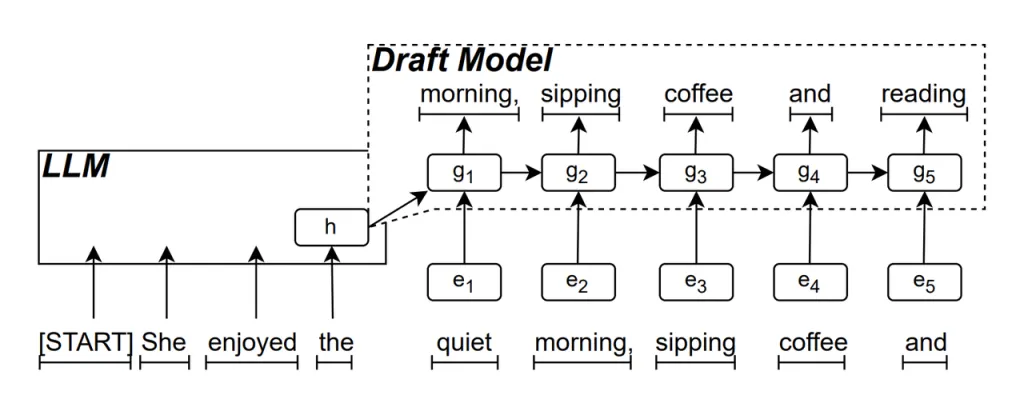
RNN ドラフトモデル ReDrafter の中核部分です。リカレント ニューラル ネットワーク (RNN) を使用して、LLM の隠れた状態に基づいて次の単語シーケンスを予測します。これにより、時間的な依存関係がキャプチャされ、予測の精度が向上します。
このモデルの動作方法は次のとおりです。LLM がテキストを生成するとき、最初に最初の単語を生成し、次に RNN ドラフト モデルがこの単語と LLM の最後のレイヤーの隠し状態を入力として使用してビーム検索を実行し、複数の候補単語シーケンスを生成します。
一度に 1 つの単語を生成する従来の自己回帰 LLM とは異なり、ReDrafter は RNN ドラフト モデルの予測を通じて各デコード ステップで複数の単語を生成できるため、検証のために LLM を呼び出す回数が大幅に削減され、全体的な推論速度が向上します。
動的ツリーアテンションアルゴリズム ビーム探索の結果を最適化するアルゴリズムです。
ビーム検索プロセス中に、複数の候補シーケンスが生成されますが、多くの場合、それらの先頭は同じです。ダイナミック ツリー アテンション アルゴリズムは、これらの共通の先頭を識別し、検証が必要な単語からそれらを削除して、LLM が処理する必要があるデータの量を削減します。
場合によっては、このアルゴリズムにより、検証が必要な単語数を 30% ~ 60% 削減できます。つまり、Dynamic Tree Attention アルゴリズムを使用すると、ReDrafter は計算リソースをより効率的に活用でき、推論速度がさらに向上します。
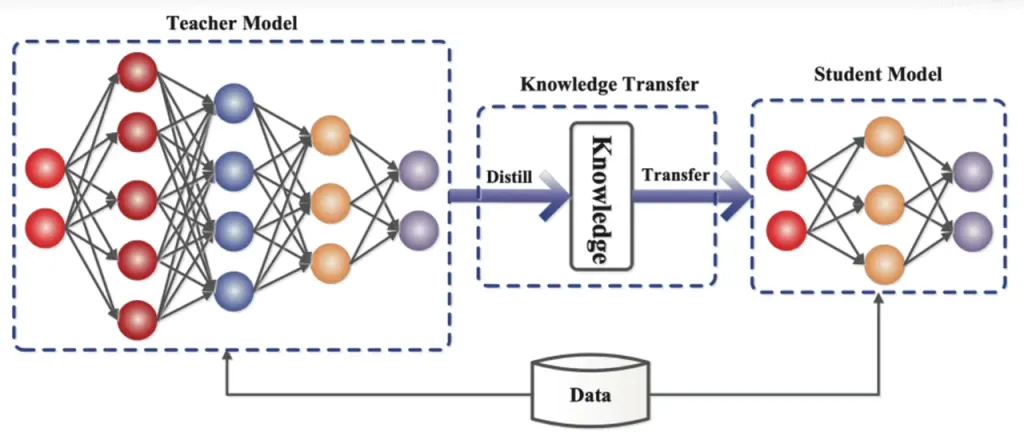
知識蒸留 は、大規模で複雑なモデル (教師モデル) からより小さく単純なモデル (生徒モデル) に知識を転送するモデル圧縮技術です。ReDrafter では、RNN ドラフト モデルが生徒モデルとして機能し、知識蒸留を通じて LLM (教師モデル) から学習します。
詳細には、蒸留トレーニング プロセス中に、大規模言語モデル (LLM) が次の可能性のある単語の一連の「確率分布」を提供します。開発者は、この確率分布データを使用して、リカレント ニューラル ネットワーク (RNN) ドラフト モデルをトレーニングし、2 つのモデルの確率分布の差を計算し、最適化アルゴリズムによってこの差を最小限に抑えます。
このプロセスの間、RNN ドラフト モデルは LLM の確率予測パターンを継続的に学習し、実際のアプリケーションで LLM に類似したテキストを生成できるようになります。
知識蒸留トレーニングを通じて、RNN ドラフト モデルは言語のルールとパターンをより正確に捉え、LLM の出力をより正確に予測します。サイズが小さく、計算コストが低いため、限られたハードウェア条件下でも ReDrafter の全体的なパフォーマンスが大幅に向上します。
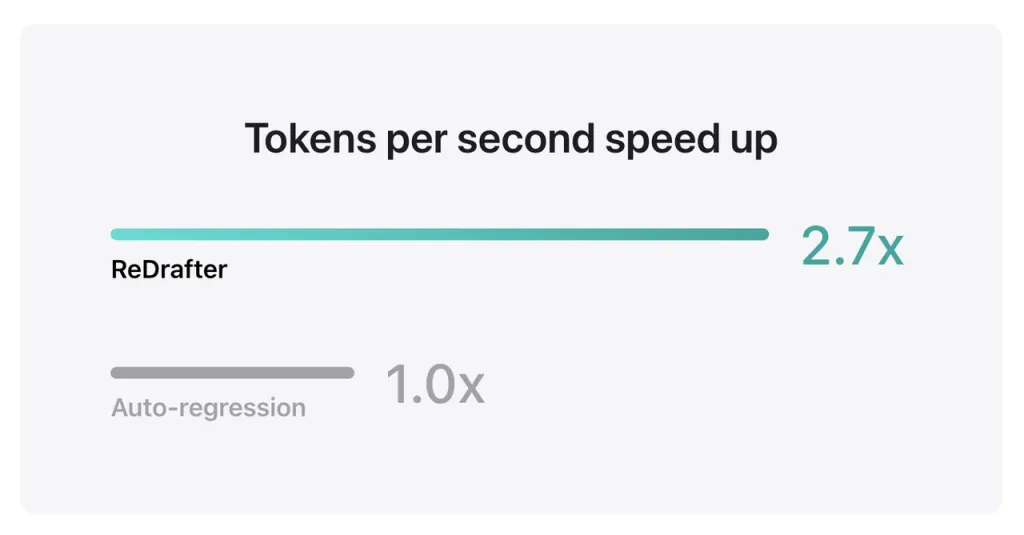
Apple のベンチマーク結果によると、NVIDIA H100 GPU 上で ReDrafter の TensorRT-LLM と統合された数十億のパラメータを持つプロダクション モデルを使用すると、Greedy Decoding によって 2.7 秒あたりに生成されるトークンの数が XNUMX 倍に増加しました。
さらに、Apple 独自の M2 Ultra Metal GPU では、ReDrafter は推論速度を 2.3 倍向上させました。Apple の研究者は、「LLM は実稼働アプリケーションの駆動にますます使用されるようになっているため、推論効率を向上させることで計算コストに影響を与え、ユーザー側のレイテンシを削減できます」と述べています。
注目すべきは、ReDrafter は出力品質を維持しながら GPU リソースの需要を減らし、リソースが制限された環境でも LLM を効率的に実行できるようにし、さまざまなハードウェア プラットフォームで LLM を使用するための新しい可能性を提供していることです。
Apple はすでにこの技術を GitHub でオープンソース化しており、将来的には NVIDIA 以外の企業もこの技術の恩恵を受けることになるだろう。
ソースから もし
免責事項: 上記の情報は、Chovm.com とは無関係に ifanr.com によって提供されています。Chovm.com は、販売者および製品の品質と信頼性について一切の表明および保証を行いません。Chovm.com は、コンテンツの著作権に関する違反に対する一切の責任を明示的に否認します。




 বাংলা
বাংলা Nederlands
Nederlands English
English Français
Français Deutsch
Deutsch हिन्दी
हिन्दी Bahasa Indonesia
Bahasa Indonesia Italiano
Italiano 日本語
日本語 한국어
한국어 Bahasa Melayu
Bahasa Melayu മലയാളം
മലയാളം پښتو
پښتو فارسی
فارسی Polski
Polski Português
Português Русский
Русский Español
Español Kiswahili
Kiswahili ไทย
ไทย Türkçe
Türkçe اردو
اردو Tiếng Việt
Tiếng Việt isiXhosa
isiXhosa Zulu
Zulu