
長い間待ち望まれていた Xiaohongshu の翻訳機能が、ついに 2025 年 XNUMX 月の第 XNUMX 週末に登場しました。ヒントや知っておくべきことをいくつかご紹介します。
– Xiaohongshu(Red Note)を最新バージョンにアップグレードします。
– 小紅書や電話システムの設定など、言語設定を変更してみてください。
– 現在は単一言語の翻訳のみサポートしており、混合言語や絵文字では翻訳は実行されません。
– それでもうまくいかない場合は、一部のユーザーは「kill-it」トリックを提案しています。英語でコメントを投稿し、アプリを終了してから、Xiaohongshuを再度開いて翻訳機能を有効にします。
Xiaohongshu の開発者は信じられないほど速く、ユーザーからは「これほど速いアップデートは見たことがない」という声が上がっています。これが伝説の「中国スピード」なのでしょうか?

翻訳ソフトを除いて、世界中の誰もが興奮しています(笑)。リリースからわずか1週間ですが、翻訳のパフォーマンスは素晴らしく、国境を越えた閲覧が楽になります。「u1sXNUMX」、「yyds」、「cpdd」などの中国のインターネットスラングは正確に理解され、注釈が付けられています。
- u1s1 – 正直に言うと
- yyds – 永遠に最高、不滅
- cpdd – カップル検索、カップルを探しています
私たちの同僚は、「cpdd」の意味がわからなかったと認めました。これは、人間が GPT に太刀打ちできないことの証拠です。Xiaohongshu さん、あなたが作っているのは翻訳ツールですか、それともミームの百科事典ですか? 中国語の方言も翻訳されているのがおまけです。
原文に誤りがあっても、翻訳には影響しません。小紅書は注意深く注釈を付けています。

Xiaohongshuさん、本当に私に言語を教えようと思ってくださっているんですね、感動しました。
明らかに、Xiaohongshuの新しい翻訳機能は、 大規模な言語モデル、そしてユーザーはその背後にあるモデルをテストすることに熱心です。たとえば、簡単な翻訳から始めて、数行の詩を書きます。

モールス信号を入力して翻訳する人もいますが、これはスパイ スリラーではなく、小紅書です。
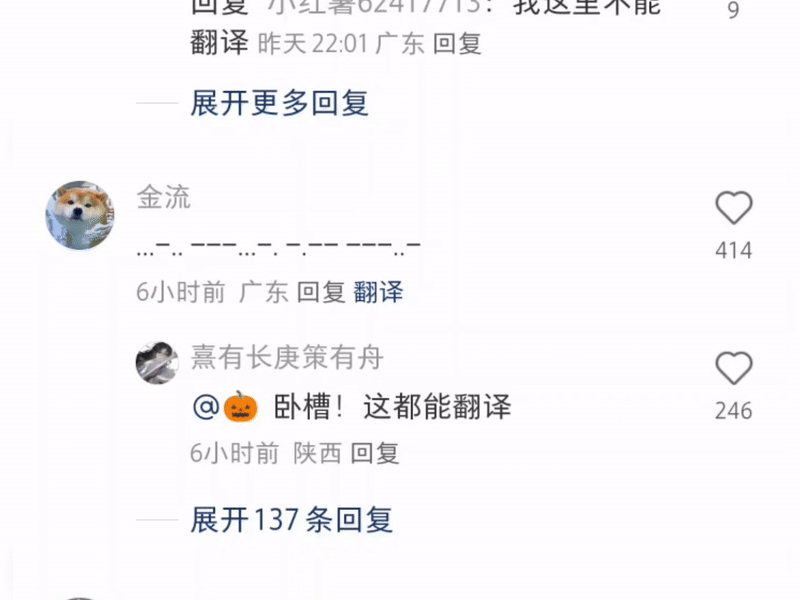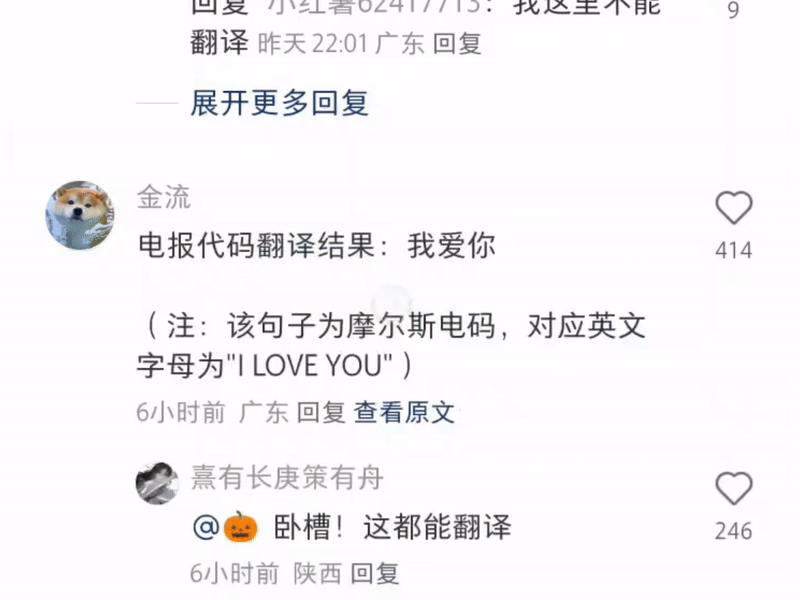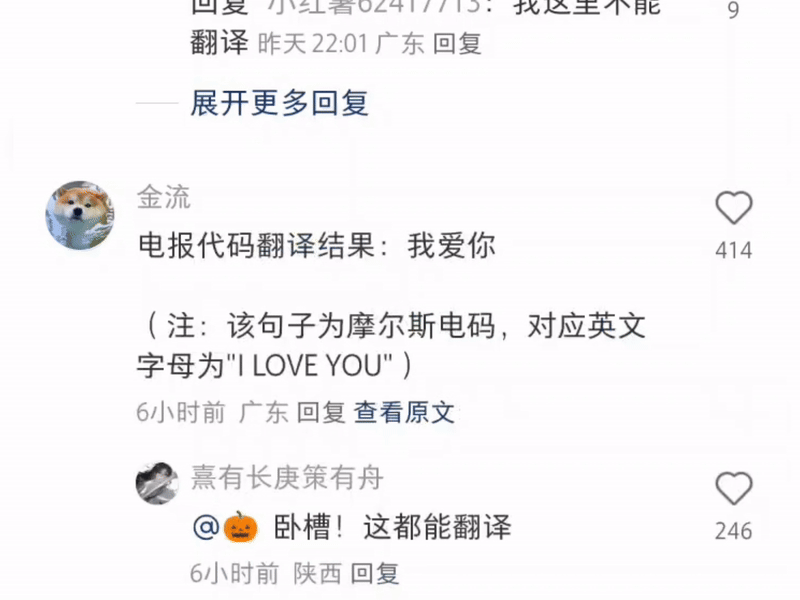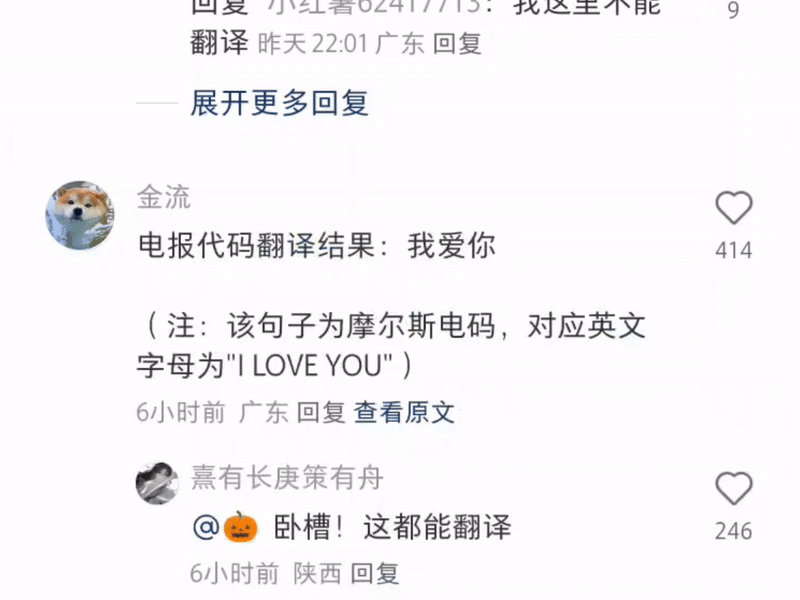
一方的に宣言します:Xiaohongshuは現在最も強力な多機能翻訳ソフトウェアです。
大規模な言語モデルを使用して翻訳タスクを処理することはすでに非常に効果的ですが、Xiaohongshu のようなコンテンツが豊富なソーシャル プラットフォームでは、まだ多くの課題が残っています。
言語の多様性は最も難しい問題です。慣用句や俗語など、文化特有の用語、慣用表現、比喩などは、正確に翻訳するのが難しい場合があります。
また、モデルが翻訳が必要なものおよび変更しないままにしておく必要があるものをうまく区別できない名前やニックネームもあります。
たとえば、「オレンジマン」は「橙人」と直訳されていますが、実際にはトランプ氏を指しています。

正確さ以外に、一般ユーザーは翻訳に必要な計算リソースを認識しない可能性があります。
Xiaohongshu のようにコンテンツが豊富なプラットフォームでは、ユーザーは数文字の手紙や数百語に及ぶメモを投稿することがあります。それに比べて、長いコンテンツを翻訳すると、より多くのリソースが消費され、システム負荷が増加します。
さらに、さまざまな国のユーザーがいるため、タイムゾーンが広く分散しているため、システムの読み込み時間が遅くなることはほとんどありません。
双方が起きているとき、タイムゾーンの短い重複により翻訳リクエストが急増し、システムが短時間に大量の同時リクエストを処理する必要が生じる可能性があり、これは同時処理能力の重要なテストとなります。
小紅書はかっこよすぎる
新しい翻訳機能がどのモデルを使用するかについては、まだ正確な情報がありません。一部のユーザーの「調査」によると、GPT であるようです。一部のユーザーは「調査」し、Zhipu であることがわかりました。

コストの問題を考慮すると、確実なことは言えません。GPT には多数のパラメータがあり、計算コストも高いため、リソースが制限された環境での展開には適していません。
より実現可能なオプションとしては、学生モデルを選択し、蒸留用の教師モデルとして GPT を使用することです。学生モデルは通常、パラメータが少なく推論速度が速いですが、教師モデルの機能を保持しようとします。
同時に、このアプローチは Xiaohongshu にとってより有望である可能性があります。
Xiaohongshu は長年、大規模言語モデルやマルチモーダル システムなどの AI テクノロジーを研究してきましたが、常にアルゴリズムの最適化に重点を置いてきました。同社はこれまでにも、いくつかの小さな AI 機能を開発してきました。
2024年のAAAIカンファレンスで、Xiaohongshuの検索アルゴリズムチームがモデル蒸留の新しいアイデアを提案したことを知っている人はほとんどいません。

Xiaohongshuの検索アルゴリズムチームは、革新的なフレームワークを導入しました。 大規模モデル推論機能の抽出中に負のサンプル知識を最大限に活用する.
「ネガティブ サンプル」は興味深い概念です。従来の蒸留は一般的にポジティブなサンプルのみに焦点を当てていますが、これは理解できます。教師は生徒に問題を解決する正しい方法を教え、生徒が理解して模倣できるようにします。
しかし、学生時代には、間違いや理解が不十分だった部分を記録する「間違い帳」もつけていたのではないでしょうか。 これらの間違いは「ネガティブサンプル」ですXiaohongshu のコメント欄では、不正確な翻訳がネガティブなサンプルになっています。
「間違い」に重要な情報が含まれているのと同様に、ネガティブサンプルは、学生モデルが誤った予測を識別し、識別能力を高め、難しいサンプルの処理を改善し、複雑な言語表現の一貫性を維持するのに役立ちます。
例えば、コメント欄で海外の友人と金融用語について議論したい場合、「bank」という単語が頻繁に登場するかもしれません。この単語には「riverbank」などの意味もあり、動詞としても使えます。
ネガティブサンプル学習を通じて、モデルは多義的な表現を認識し、翻訳ロジックを修正し、より自然なコンテンツを生成するようにトレーニングされます。
ネガティブサンプルの利点は、あまり一般的でない言語のサポートにも及びます。これはアメリカのユーザーだけに向けたものではないことに注意することが重要です。セルビア、ペルー、オーストラリアの一部の先住民地域など、世界中のユーザーが参加しています。

ネガティブサンプル(一般的な翻訳エラーパターンを含む)を利用することで、学生モデルは頻繁に発生するエラーを識別して回避し、リソースの少ない言語の翻訳機能を強化することができます。
Xiaohongshuチームが提案したフレームワーク 蒸留の革新的な応用であるは、当初は大規模な言語モデルから複雑な推論機能を抽出し、それを専門の小さなモデルに転送することを目的としていました。当時は、具体的にどのようなタスクを達成できるかは明確ではなく、翻訳は焦点ではなかったようです。
おそらく、この枠組みが1年後に小紅書が国際コミュニケーションの架け橋となるのに役立つとは誰も知らなかっただろう。
諺にもあるように、チャンスは常に準備のできた者に訪れる。
ソースから もし
免責事項: 上記の情報は、Chovm.com とは無関係に ifanr.com によって提供されています。Chovm.com は、販売者および製品の品質と信頼性について一切の表明および保証を行いません。Chovm.com は、コンテンツの著作権に関する違反に対する一切の責任を明示的に否認します。



