
Baru-baru ini, Apple dan Nvidia mengumumkan kerjasama yang bertujuan untuk mempercepat dan mengoptimumkan kelajuan inferens model bahasa besar (LLM).
Untuk menangani ketidakcekapan dan lebar jalur memori terhad inferens LLM autoregresif tradisional, penyelidik pembelajaran mesin Apple mengeluarkan dan sumber terbuka teknik penyahkodan spekulatif yang dipanggil "ReDrafter" (Model Draf Berulang) pada awal tahun 2024.
Pada masa ini, ReDrafter telah disepadukan ke dalam penyelesaian inferens boleh skala Nvidia "TensorRT-LLM." Penyelesaian ini ialah perpustakaan sumber terbuka berdasarkan rangka kerja pengkompil pembelajaran mendalam "TensorRT", yang direka khusus untuk mengoptimumkan inferens LLM dan menyokong kaedah penyahkodan spekulatif seperti "Medusa."
Walau bagaimanapun, memandangkan algoritma ReDrafter menggunakan pengendali yang tidak digunakan sebelum ini, Nvidia telah menambah pengendali baharu atau menjadikan yang sedia ada awam, meningkatkan keupayaan TensorRT-LLM dengan ketara untuk menyesuaikan diri dengan model yang kompleks dan kaedah penyahkodan.
Dilaporkan bahawa ReDrafter mempercepatkan proses inferens model bahasa besar (LLM) melalui tiga teknologi utama:
- Model Draf RNN
- Algoritma Perhatian Pokok Dinamik
- Latihan Penyulingan Ilmu
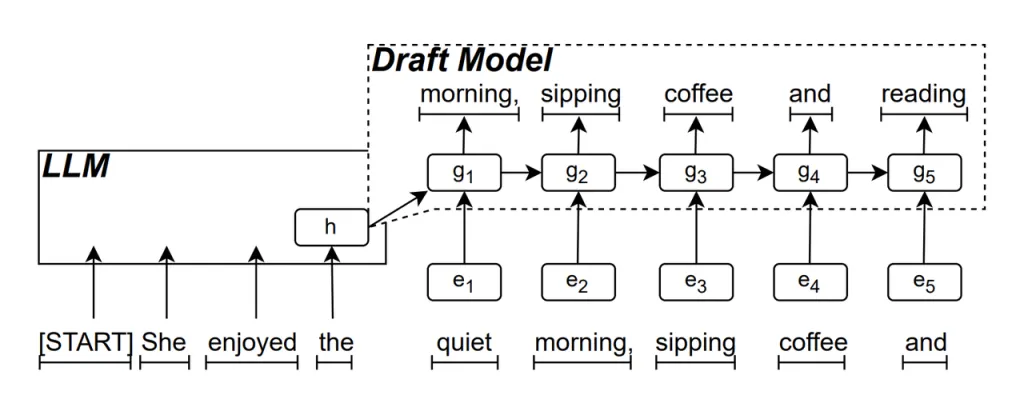
Model Draf RNN ialah bahagian teras ReDrafter. Ia menggunakan Rangkaian Neural Berulang (RNN) untuk meramalkan kemungkinan urutan perkataan seterusnya berdasarkan keadaan tersembunyi LLM. Ini menangkap kebergantungan sementara dan meningkatkan ketepatan ramalan.
Cara model ini berfungsi ialah: apabila LLM menjana teks, ia mula-mula menjana perkataan awal, kemudian Model Draf RNN menggunakan perkataan ini dan keadaan tersembunyi lapisan terakhir LLM sebagai input untuk melakukan carian pancaran, menjana berbilang urutan perkataan calon.
Tidak seperti LLM autoregresif tradisional yang menjana satu perkataan pada satu masa, ReDrafter boleh menjana berbilang perkataan pada setiap langkah penyahkodan melalui ramalan Model Draf RNN, dengan ketara mengurangkan bilangan kali LLM perlu dipanggil untuk pengesahan, dengan itu meningkatkan kelajuan inferens keseluruhan.
Algoritma Perhatian Pokok Dinamik ialah algoritma yang mengoptimumkan hasil carian rasuk.
Semasa proses carian pancaran, berbilang jujukan calon dijana, yang selalunya mempunyai permulaan yang sama. Algoritma Perhatian Pokok Dinamik mengenal pasti permulaan biasa ini dan mengeluarkannya daripada perkataan yang perlu disahkan, mengurangkan jumlah data yang perlu diproses oleh LLM.
Dalam sesetengah kes, algoritma ini boleh mengurangkan bilangan perkataan yang perlu disahkan sebanyak 30% hingga 60%. Ini bermakna dengan Algoritma Perhatian Pokok Dinamik, ReDrafter boleh menggunakan sumber pengiraan dengan lebih cekap, seterusnya meningkatkan kelajuan inferens.
Penyulingan Pengetahuan ialah teknik pemampatan model yang memindahkan pengetahuan daripada model yang besar dan kompleks (model guru) kepada model yang lebih kecil dan ringkas (model pelajar). Dalam ReDrafter, Model Draf RNN bertindak sebagai model pelajar, belajar daripada LLM (model guru) melalui penyulingan pengetahuan.
Secara terperinci, semasa proses latihan penyulingan, model bahasa besar (LLM) menyediakan satu siri "taburan kebarangkalian" untuk perkataan yang mungkin seterusnya. Pembangun menggunakan data taburan kebarangkalian ini untuk melatih model draf Rangkaian Neural Berulang (RNN), kemudian mengira perbezaan antara taburan kebarangkalian kedua-dua model dan meminimumkan perbezaan ini melalui algoritma pengoptimuman.
Semasa proses ini, model draf RNN secara berterusan mempelajari corak ramalan kebarangkalian LLM, membolehkannya menjana teks yang serupa dengan LLM dalam aplikasi praktikal.
Melalui latihan penyulingan pengetahuan, model draf RNN lebih menangkap peraturan dan corak bahasa, dengan itu lebih tepat meramalkan output LLM. Oleh kerana saiznya yang lebih kecil dan kos pengiraan yang lebih rendah, ia meningkatkan prestasi keseluruhan ReDrafter dengan ketara dalam keadaan perkakasan yang terhad.
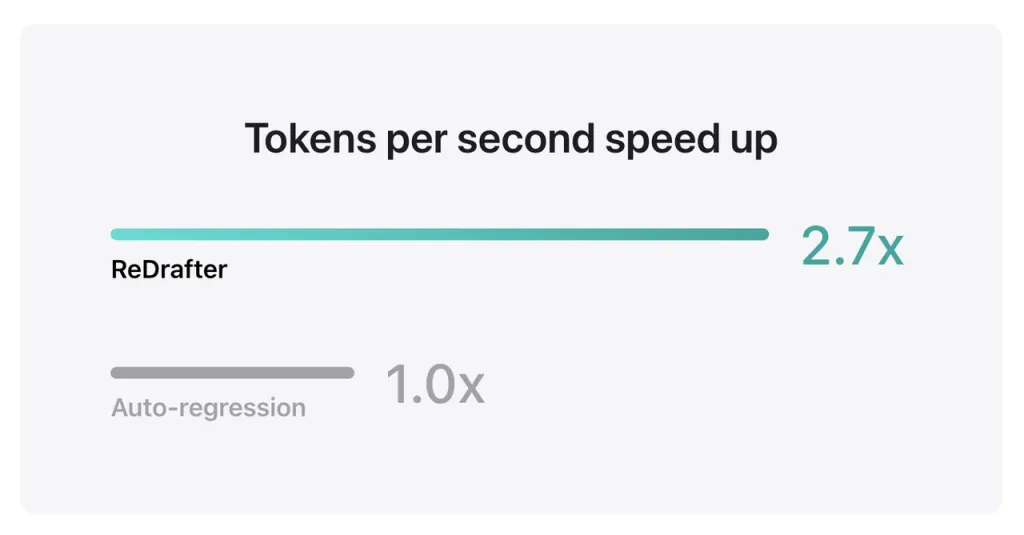
Keputusan penanda aras Apple menunjukkan bahawa apabila menggunakan model pengeluaran dengan berbilion parameter yang disepadukan dengan TensorRT-LLM ReDrafter pada GPU NVIDIA H100, bilangan token yang dijana sesaat oleh Penyahkodan Greedy meningkat sebanyak 2.7 kali ganda.
Selain itu, pada GPU Ultra Metal M2 Apple sendiri, ReDrafter mencapai peningkatan kelajuan inferens sebanyak 2.3 kali. Penyelidik Apple menyatakan, "Memandangkan LLM semakin digunakan untuk memacu aplikasi pengeluaran, meningkatkan kecekapan inferens boleh memberi kesan kepada kos pengiraan dan mengurangkan kependaman akhir pengguna."
Perlu diingat bahawa sambil mengekalkan kualiti output, ReDrafter mengurangkan permintaan untuk sumber GPU, membolehkan LLM berjalan dengan cekap walaupun dalam persekitaran yang terhad sumber, memberikan kemungkinan baharu untuk penggunaan LLM pada pelbagai platform perkakasan.
Apple telah pun menggunakan sumber terbuka teknologi ini di GitHub, dan pada masa hadapan, syarikat yang mendapat manfaat daripadanya mungkin akan merangkumi lebih daripada sekadar NVIDIA.
Sumber daripada ifan
Penafian: Maklumat yang dinyatakan di atas disediakan oleh ifanr.com, secara bebas daripada Chovm.com. Chovm.com tidak membuat perwakilan dan jaminan tentang kualiti dan kebolehpercayaan penjual dan produk. Chovm.com secara jelas menafikan sebarang liabiliti untuk pelanggaran yang berkaitan dengan hak cipta kandungan.




 বাংলা
বাংলা Nederlands
Nederlands English
English Français
Français Deutsch
Deutsch हिन्दी
हिन्दी Bahasa Indonesia
Bahasa Indonesia Italiano
Italiano 日本語
日本語 한국어
한국어 Bahasa Melayu
Bahasa Melayu മലയാളം
മലയാളം پښتو
پښتو فارسی
فارسی Polski
Polski Português
Português Русский
Русский Español
Español Kiswahili
Kiswahili ไทย
ไทย Türkçe
Türkçe اردو
اردو Tiếng Việt
Tiếng Việt isiXhosa
isiXhosa Zulu
Zulu