
Recentemente, a Apple e a Nvidia anunciaram uma colaboração com o objetivo de acelerar e otimizar a velocidade de inferência de grandes modelos de linguagem (LLMs).
Para lidar com as ineficiências e a largura de banda de memória limitada da inferência LLM autorregressiva tradicional, os pesquisadores de aprendizado de máquina da Apple lançaram e disponibilizaram de código aberto uma técnica de decodificação especulativa chamada “ReDrafter” (Recurrent Draft Model) no início de 2024.
Atualmente, o ReDrafter foi integrado à solução de inferência escalável da Nvidia, “TensorRT-LLM”. Esta solução é uma biblioteca de código aberto baseada na estrutura do compilador de aprendizado profundo “TensorRT”, projetada especificamente para otimizar a inferência LLM e oferecer suporte a métodos de decodificação especulativa como “Medusa”.
No entanto, como os algoritmos do ReDrafter usam operadores não utilizados anteriormente, a Nvidia adicionou novos operadores ou tornou os existentes públicos, melhorando significativamente a capacidade do TensorRT-LLM de se adaptar a modelos complexos e métodos de decodificação.
É relatado que o ReDrafter acelera o processo de inferência de grandes modelos de linguagem (LLM) por meio de três tecnologias principais:
- Modelo de rascunho RNN
- Algoritmo de atenção de árvore dinâmica
- Treinamento de Destilação de Conhecimento
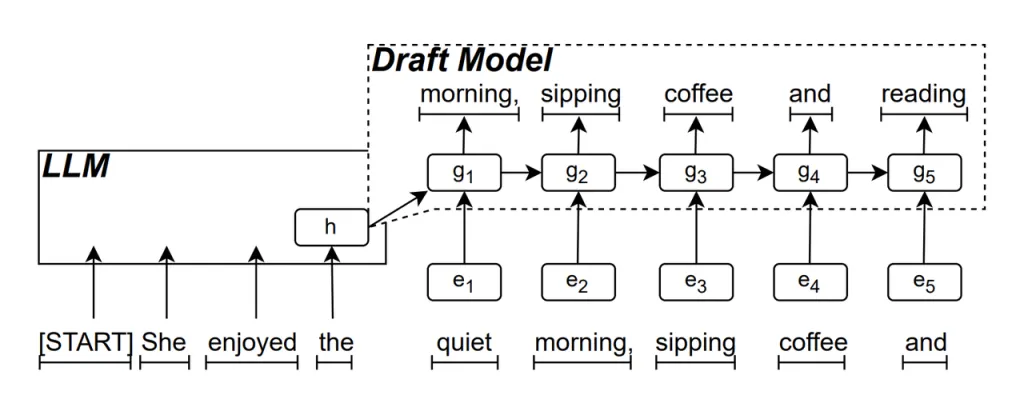
Modelo de rascunho RNN é a parte central do ReDrafter. Ele usa uma Rede Neural Recorrente (RNN) para prever a próxima sequência de palavras possível com base nos estados ocultos do LLM. Isso captura dependências temporais e melhora a precisão da previsão.
O funcionamento desse modelo é o seguinte: quando o LLM gera texto, ele primeiro gera uma palavra inicial e, então, o RNN Draft Model usa essa palavra e o estado oculto da última camada do LLM como entrada para executar a pesquisa de feixe, gerando várias sequências de palavras candidatas.
Ao contrário dos LLMs autorregressivos tradicionais que geram uma palavra por vez, o ReDrafter pode gerar várias palavras em cada etapa de decodificação por meio das previsões do RNN Draft Model, reduzindo significativamente o número de vezes que o LLM precisa ser chamado para validação, melhorando assim a velocidade geral de inferência.
Algoritmo de atenção de árvore dinâmica é um algoritmo que otimiza os resultados da pesquisa de feixes.
Durante o processo de busca de feixe, várias sequências candidatas são geradas, que frequentemente têm o mesmo começo. O Dynamic Tree Attention Algorithm identifica esses começos comuns e os remove das palavras que precisam ser validadas, reduzindo a quantidade de dados que o LLM precisa processar.
Em alguns casos, esse algoritmo pode reduzir o número de palavras que precisam ser validadas em 30% a 60%. Isso significa que, com o Dynamic Tree Attention Algorithm, o ReDrafter pode utilizar recursos computacionais de forma mais eficiente, melhorando ainda mais a velocidade de inferência.
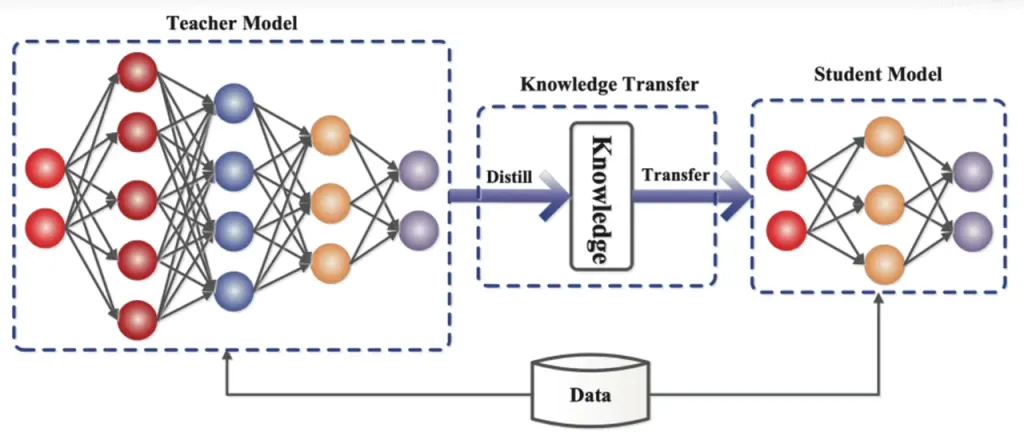
Destilação de Conhecimento é uma técnica de compressão de modelo que transfere o conhecimento de um modelo grande e complexo (modelo do professor) para um modelo menor e mais simples (modelo do aluno). No ReDrafter, o RNN Draft Model atua como o modelo do aluno, aprendendo do LLM (modelo do professor) por meio da destilação do conhecimento.
Em detalhes, durante o processo de treinamento de destilação, um grande modelo de linguagem (LLM) fornece uma série de “distribuições de probabilidade” para as próximas palavras possíveis. Os desenvolvedores usam esses dados de distribuição de probabilidade para treinar um modelo de rascunho de Rede Neural Recorrente (RNN), então calculam a diferença entre as distribuições de probabilidade dos dois modelos e minimizam essa diferença por meio de algoritmos de otimização.
Durante esse processo, o modelo de rascunho da RNN aprende continuamente os padrões de previsão de probabilidade do LLM, permitindo que ele gere texto semelhante ao LLM em aplicações práticas.
Por meio do treinamento de destilação de conhecimento, o modelo de rascunho RNN captura melhor as regras e padrões da linguagem, prevendo assim com mais precisão a saída do LLM. Devido ao seu tamanho menor e menor custo computacional, ele melhora significativamente o desempenho geral do ReDrafter sob condições limitadas de hardware.
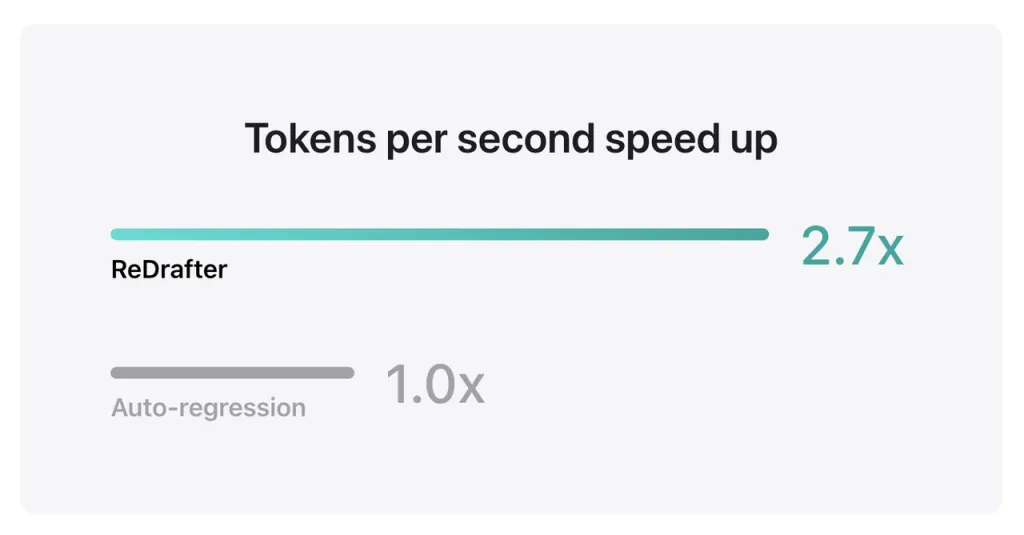
Os resultados de benchmark da Apple mostram que ao usar o modelo de produção com bilhões de parâmetros integrados ao TensorRT-LLM do ReDrafter na GPU NVIDIA H100, o número de tokens gerados por segundo pelo Greedy Decoding aumentou em 2.7 vezes.
Além disso, na GPU M2 Ultra Metal da Apple, o ReDrafter atingiu uma melhoria de velocidade de inferência de 2.3 vezes. Os pesquisadores da Apple declararam: "À medida que os LLMs são cada vez mais usados para conduzir aplicativos de produção, melhorar a eficiência da inferência pode impactar os custos computacionais e reduzir a latência do usuário final".
Vale ressaltar que, ao mesmo tempo em que mantém a qualidade da saída, o ReDrafter reduz a demanda por recursos de GPU, permitindo que os LLMs sejam executados com eficiência mesmo em ambientes com recursos limitados, oferecendo novas possibilidades para o uso de LLMs em diversas plataformas de hardware.
A Apple já tornou essa tecnologia de código aberto no GitHub e, no futuro, as empresas que se beneficiarão dela provavelmente incluirão mais do que apenas a NVIDIA.
Retirado de se um
Isenção de responsabilidade: as informações estabelecidas acima são fornecidas por ifanr.com, independentemente do Chovm.com. Chovm.com não faz nenhuma representação e garantia quanto à qualidade e confiabilidade do vendedor e dos produtos. Chovm.com isenta-se expressamente de qualquer responsabilidade por violações relativas aos direitos autorais do conteúdo.




 বাংলা
বাংলা Nederlands
Nederlands English
English Français
Français Deutsch
Deutsch हिन्दी
हिन्दी Bahasa Indonesia
Bahasa Indonesia Italiano
Italiano 日本語
日本語 한국어
한국어 Bahasa Melayu
Bahasa Melayu മലയാളം
മലയാളം پښتو
پښتو فارسی
فارسی Polski
Polski Português
Português Русский
Русский Español
Español Kiswahili
Kiswahili ไทย
ไทย Türkçe
Türkçe اردو
اردو Tiếng Việt
Tiếng Việt isiXhosa
isiXhosa Zulu
Zulu