
Недавно Apple и Nvidia объявили о сотрудничестве, направленном на ускорение и оптимизацию скорости вывода больших языковых моделей (LLM).
Чтобы устранить неэффективность и ограниченную пропускную способность памяти традиционного авторегрессионного вывода LLM, исследователи машинного обучения Apple в начале 2024 года выпустили и открыли исходный код спекулятивной методики декодирования под названием «ReDrafter» (Recurrent Draft Model).
В настоящее время ReDrafter интегрирован в масштабируемое решение вывода Nvidia «TensorRT-LLM». Это решение представляет собой библиотеку с открытым исходным кодом, основанную на фреймворке компилятора глубокого обучения «TensorRT», специально разработанную для оптимизации вывода LLM и поддержки спекулятивных методов декодирования, таких как «Medusa».
Однако, поскольку алгоритмы ReDrafter используют ранее не использовавшиеся операторы, Nvidia добавила новые операторы или сделала существующие общедоступными, что значительно повысило способность TensorRT-LLM адаптироваться к сложным моделям и методам декодирования.
Сообщается, что ReDrafter ускоряет процесс вывода больших языковых моделей (LLM) с помощью трех ключевых технологий:
- Проект модели RNN
- Алгоритм динамического внимания к дереву
- Обучение извлечению знаний
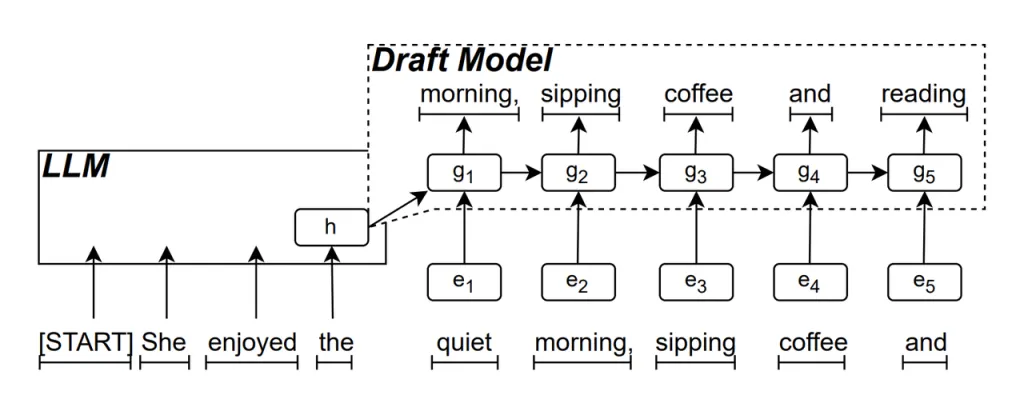
Проект модели RNN является основной частью ReDrafter. Он использует рекуррентную нейронную сеть (RNN) для прогнозирования следующей возможной последовательности слов на основе скрытых состояний LLM. Это фиксирует временные зависимости и повышает точность прогнозирования.
Эта модель работает следующим образом: когда LLM генерирует текст, он сначала генерирует начальное слово, затем черновая модель RNN использует это слово и скрытое состояние последнего слоя LLM в качестве входных данных для выполнения лучевого поиска, генерируя несколько последовательностей слов-кандидатов.
В отличие от традиционных авторегрессионных LLM, которые генерируют одно слово за раз, ReDrafter может генерировать несколько слов на каждом этапе декодирования с помощью прогнозов модели RNN Draft, что значительно сокращает количество вызовов LLM для проверки, тем самым повышая общую скорость вывода.
Алгоритм динамического внимания к дереву алгоритм, оптимизирующий результаты поиска луча.
В процессе поиска луча генерируется несколько последовательностей кандидатов, которые часто имеют одинаковое начало. Алгоритм Dynamic Tree Attention определяет эти общие начала и удаляет их из слов, которые необходимо проверить, сокращая объем данных, которые необходимо обработать LLM.
В некоторых случаях этот алгоритм может сократить количество слов, которые необходимо проверить, на 30–60%. Это означает, что с помощью алгоритма Dynamic Tree Attention Algorithm ReDrafter может более эффективно использовать вычислительные ресурсы, что еще больше повышает скорость вывода.
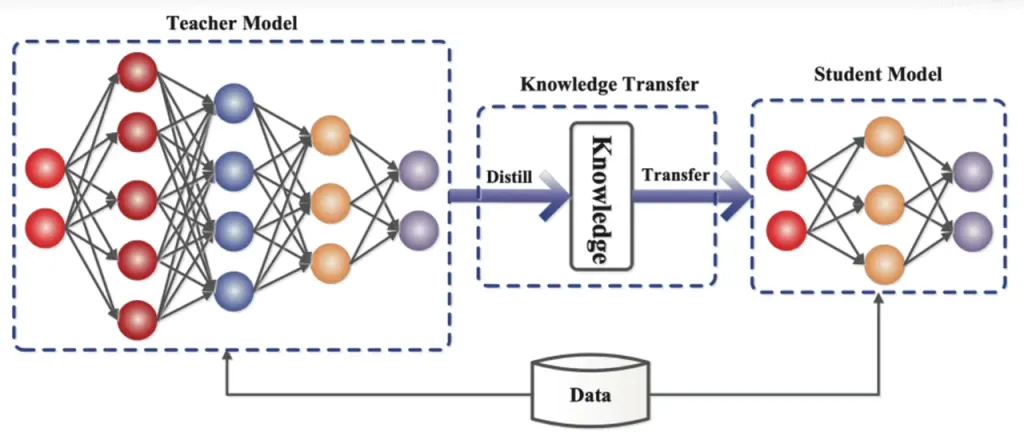
Дистилляция знаний это метод сжатия модели, который переносит знания из большой, сложной модели (модель учителя) в меньшую, более простую модель (модель ученика). В ReDrafter черновая модель RNN выступает в качестве модели ученика, обучаясь у LLM (модель учителя) посредством дистилляции знаний.
В деталях, во время процесса обучения дистилляции большая языковая модель (LLM) предоставляет ряд «распределений вероятностей» для следующих возможных слов. Разработчики используют эти данные распределения вероятностей для обучения черновой модели рекуррентной нейронной сети (RNN), затем вычисляют разницу между распределениями вероятностей двух моделей и минимизируют эту разницу с помощью алгоритмов оптимизации.
В ходе этого процесса черновая модель RNN непрерывно изучает закономерности вероятностного прогнозирования LLM, что позволяет ей генерировать текст, аналогичный LLM, в практических приложениях.
Благодаря обучению дистилляции знаний черновая модель RNN лучше фиксирует правила и шаблоны языка, тем самым точнее предсказывая выход LLM. Благодаря своему меньшему размеру и меньшим вычислительным затратам она значительно повышает общую производительность ReDrafter в условиях ограниченного оборудования.
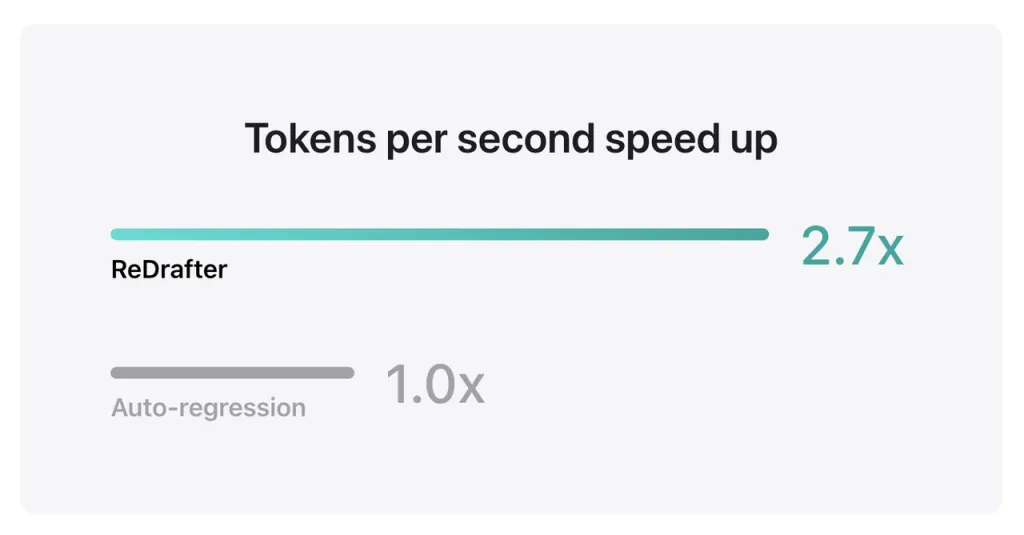
Результаты тестов Apple показывают, что при использовании производственной модели с миллиардами параметров, интегрированной с TensorRT-LLM от ReDrafter на графическом процессоре NVIDIA H100, количество токенов, генерируемых в секунду методом жадного декодирования, увеличивается в 2.7 раза.
Кроме того, на собственном графическом процессоре Apple M2 Ultra Metal ReDrafter добился улучшения скорости вывода в 2.3 раза. Исследователи Apple заявили: «Поскольку LLM все чаще используются для управления производственными приложениями, повышение эффективности вывода может повлиять на вычислительные затраты и сократить задержку на стороне пользователя».
Стоит отметить, что, сохраняя качество вывода, ReDrafter снижает потребность в ресурсах графического процессора, позволяя LLM эффективно работать даже в средах с ограниченными ресурсами, предоставляя новые возможности для использования LLM на различных аппаратных платформах.
Apple уже открыла исходный код этой технологии на GitHub, и в будущем к числу компаний, которые смогут воспользоваться ею, вероятно, будут относиться не только NVIDIA.
Источник из ифанр
Отказ от ответственности: информация, изложенная выше, предоставлена ifanr.com независимо от Chovm.com. Chovm.com не делает никаких заявлений и не дает никаких гарантий относительно качества и надежности продавца и продукции. Chovm.com категорически отказывается от какой-либо ответственности за нарушения авторских прав на контент.



