
เมื่อไม่นานนี้ Apple และ Nvidia ได้ประกาศความร่วมมือเพื่อเร่งและเพิ่มประสิทธิภาพความเร็วในการอนุมานของโมเดลภาษาขนาดใหญ่ (LLM)
เพื่อแก้ไขความไม่มีประสิทธิภาพและแบนด์วิดท์หน่วยความจำที่จำกัดของการอนุมาน LLM อัตโนมัติถดถอยแบบดั้งเดิม นักวิจัยการเรียนรู้ของเครื่องของ Apple เปิดตัวและโอเพนซอร์สเทคนิคการถอดรหัสเชิงคาดเดาที่เรียกว่า "ReDrafter" (Recurrent Draft Model) ก่อนหน้านี้ในปี 2024
ปัจจุบัน ReDrafter ได้ถูกรวมเข้าไว้ในโซลูชันการอนุมานแบบปรับขนาดได้ของ Nvidia “TensorRT-LLM” โซลูชันนี้เป็นไลบรารีโอเพ่นซอร์สที่ใช้เฟรมเวิร์กคอมไพเลอร์การเรียนรู้เชิงลึก “TensorRT” ซึ่งได้รับการออกแบบมาโดยเฉพาะเพื่อเพิ่มประสิทธิภาพการอนุมาน LLM และรองรับวิธีการถอดรหัสเชิงคาดเดา เช่น “Medusa”
อย่างไรก็ตาม เนื่องจากอัลกอริทึมของ ReDrafter ใช้ตัวดำเนินการที่ไม่เคยใช้งานมาก่อน Nvidia จึงได้เพิ่มตัวดำเนินการใหม่ๆ หรือเผยแพร่ตัวดำเนินการที่มีอยู่แล้ว ซึ่งช่วยเพิ่มความสามารถของ TensorRT-LLM ในการปรับตัวให้เข้ากับโมเดลที่ซับซ้อนและวิธีการถอดรหัสได้อย่างมาก
มีรายงานว่า ReDrafter เร่งกระบวนการอนุมานของโมเดลภาษาขนาดใหญ่ (LLM) ผ่านเทคโนโลยีสำคัญสามประการ:
- แบบจำลองร่าง RNN
- อัลกอริทึมการให้ความสนใจต้นไม้แบบไดนามิก
- การอบรมการกลั่นความรู้
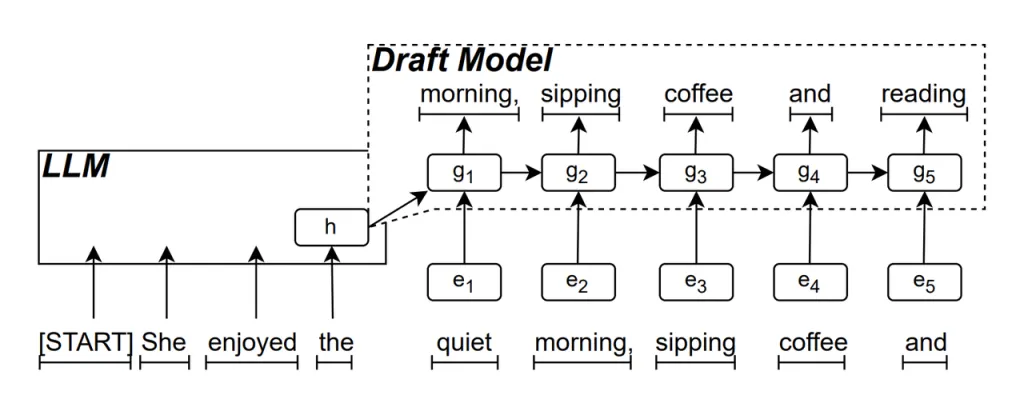
แบบจำลองร่าง RNN เป็นส่วนหลักของ ReDrafter ซึ่งใช้เครือข่ายประสาทเทียมแบบย้อนกลับ (RNN) เพื่อทำนายลำดับคำที่เป็นไปได้ถัดไปโดยอิงจากสถานะที่ซ่อนอยู่ของ LLM ซึ่งจะจับการอ้างอิงตามเวลาและปรับปรุงความแม่นยำในการทำนาย
วิธีการที่โมเดลนี้ทำงานคือ เมื่อ LLM สร้างข้อความ ระบบจะสร้างคำเริ่มต้นก่อน จากนั้นโมเดลร่าง RNN จะใช้คำนี้และสถานะที่ซ่อนอยู่ของเลเยอร์สุดท้ายของ LLM เป็นอินพุตในการค้นหาลำแสง เพื่อสร้างลำดับคำตัวเลือกหลายรายการ
ต่างจาก LLM อัตโนมัติแบบเดิมที่สร้างคำครั้งละคำ ReDrafter สามารถสร้างคำได้หลายคำในแต่ละขั้นตอนการถอดรหัสผ่านการคาดการณ์ของ RNN Draft Model ซึ่งช่วยลดจำนวนครั้งที่ต้องเรียก LLM เพื่อการตรวจสอบได้อย่างมาก จึงช่วยปรับปรุงความเร็วในการอนุมานโดยรวมให้ดีขึ้น
อัลกอริทึมการให้ความสนใจต้นไม้แบบไดนามิก เป็นอัลกอริทึมที่เพิ่มประสิทธิภาพผลการค้นหาลำแสง
ในระหว่างกระบวนการค้นหาลำแสง จะมีการสร้างลำดับผู้สมัครหลายรายการ ซึ่งมักจะมีจุดเริ่มต้นเดียวกัน อัลกอริทึม Dynamic Tree Attention จะระบุจุดเริ่มต้นทั่วไปเหล่านี้และลบออกจากคำที่ต้องตรวจสอบ ทำให้ปริมาณข้อมูลที่ LLM ต้องประมวลผลลดลง
ในบางกรณี อัลกอริทึมนี้สามารถลดจำนวนคำที่ต้องตรวจสอบลงได้ 30% ถึง 60% ซึ่งหมายความว่าด้วยอัลกอริทึม Dynamic Tree Attention Algorithm ReDrafter สามารถใช้ทรัพยากรคอมพิวเตอร์ได้อย่างมีประสิทธิภาพมากขึ้น ส่งผลให้ความเร็วในการอนุมานดีขึ้นอีกด้วย
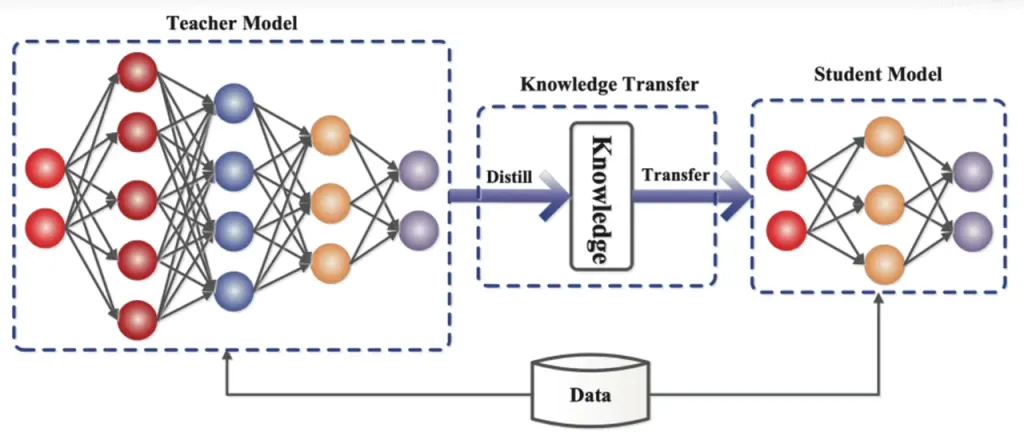
การกลั่นความรู้ เป็นเทคนิคการบีบอัดแบบจำลองที่ถ่ายโอนความรู้จากแบบจำลองขนาดใหญ่และซับซ้อน (แบบจำลองครู) ไปยังแบบจำลองขนาดเล็กและเรียบง่ายกว่า (แบบจำลองนักเรียน) ใน ReDrafter แบบจำลองร่าง RNN ทำหน้าที่เป็นแบบจำลองนักเรียน โดยเรียนรู้จาก LLM (แบบจำลองครู) ผ่านการกลั่นกรองความรู้
โดยละเอียด ในระหว่างกระบวนการฝึกอบรมการกลั่น โมเดลภาษาขนาดใหญ่ (LLM) จะให้ชุด "การแจกแจงความน่าจะเป็น" สำหรับคำที่เป็นไปได้ถัดไป นักพัฒนาใช้ข้อมูลการแจกแจงความน่าจะเป็นนี้เพื่อฝึกอบรมโมเดลร่างเครือข่ายประสาทเทียมแบบวนซ้ำ (RNN) จากนั้นคำนวณความแตกต่างระหว่างการแจกแจงความน่าจะเป็นของโมเดลทั้งสอง และลดความแตกต่างนี้ให้เหลือน้อยที่สุดโดยใช้อัลกอริทึมการเพิ่มประสิทธิภาพ
ในระหว่างกระบวนการนี้ โมเดลร่าง RNN จะเรียนรู้รูปแบบการทำนายความน่าจะเป็นของ LLM อย่างต่อเนื่อง ช่วยให้สามารถสร้างข้อความที่คล้ายกับ LLM ในแอปพลิเคชันจริงได้
ด้วยการฝึกอบรมการกลั่นกรองความรู้ โมเดลร่าง RNN สามารถจับกฎและรูปแบบของภาษาได้ดีขึ้น จึงทำนายผลลัพธ์ของ LLM ได้แม่นยำยิ่งขึ้น เนื่องจากมีขนาดเล็กกว่าและต้นทุนการคำนวณต่ำกว่า จึงช่วยปรับปรุงประสิทธิภาพโดยรวมของ ReDrafter ได้อย่างมากภายใต้เงื่อนไขฮาร์ดแวร์ที่จำกัด
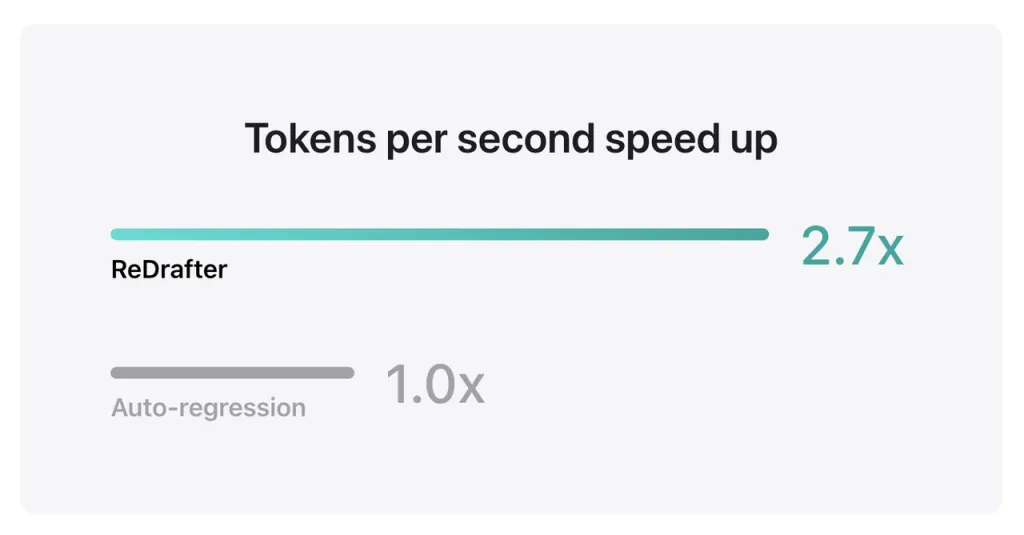
ผลการประเมินประสิทธิภาพของ Apple แสดงให้เห็นว่าเมื่อใช้โมเดลการผลิตที่มีพารามิเตอร์นับพันล้านรายการที่รวมเข้ากับ TensorRT-LLM ของ ReDrafter บน GPU NVIDIA H100 จำนวนโทเค็นที่สร้างขึ้นต่อวินาทีโดย Greedy Decoding จะเพิ่มขึ้น 2.7 เท่า
นอกจากนี้ ด้วย GPU M2 Ultra Metal ของ Apple เอง ReDrafter ยังปรับปรุงความเร็วในการอนุมานได้ 2.3 เท่า นักวิจัยของ Apple กล่าวว่า "เนื่องจาก LLM ถูกนำมาใช้เพื่อขับเคลื่อนแอปพลิเคชันการผลิตมากขึ้น การปรับปรุงประสิทธิภาพการอนุมานจึงสามารถส่งผลต่อต้นทุนการคำนวณและลดเวลาแฝงของผู้ใช้ได้"
ที่น่าสังเกตก็คือ ในขณะที่ยังคงรักษาคุณภาพเอาต์พุต ReDrafter จะลดความต้องการทรัพยากร GPU ทำให้ LLM ทำงานได้อย่างมีประสิทธิภาพแม้ในสภาพแวดล้อมที่มีทรัพยากรจำกัด อีกทั้งยังเปิดโอกาสใหม่ๆ ให้กับการใช้ LLM บนแพลตฟอร์มฮาร์ดแวร์ต่างๆ
Apple ได้เปิดซอร์สเทคโนโลยีนี้บน GitHub แล้ว และในอนาคต บริษัทต่างๆ ที่จะได้รับประโยชน์จากเทคโนโลยีนี้ก็อาจจะรวมถึงบริษัทอื่นๆ นอกเหนือไปจาก NVIDIA ด้วย
ที่มาจาก อีฟาน
ข้อสงวนสิทธิ์: ข้อมูลที่ระบุไว้ข้างต้นจัดทำโดย ifanr.com ซึ่งเป็นอิสระจาก Chovm.com Chovm.com ไม่รับรองหรือรับประกันคุณภาพและความน่าเชื่อถือของผู้ขายและผลิตภัณฑ์ Chovm.com ขอปฏิเสธความรับผิดชอบใดๆ ต่อการละเมิดลิขสิทธิ์ของเนื้อหา




 বাংলা
বাংলা Nederlands
Nederlands English
English Français
Français Deutsch
Deutsch हिन्दी
हिन्दी Bahasa Indonesia
Bahasa Indonesia Italiano
Italiano 日本語
日本語 한국어
한국어 Bahasa Melayu
Bahasa Melayu മലയാളം
മലയാളം پښتو
پښتو فارسی
فارسی Polski
Polski Português
Português Русский
Русский Español
Español Kiswahili
Kiswahili ไทย
ไทย Türkçe
Türkçe اردو
اردو Tiếng Việt
Tiếng Việt isiXhosa
isiXhosa Zulu
Zulu